## Heatmap: Classification Accuracies
### Overview
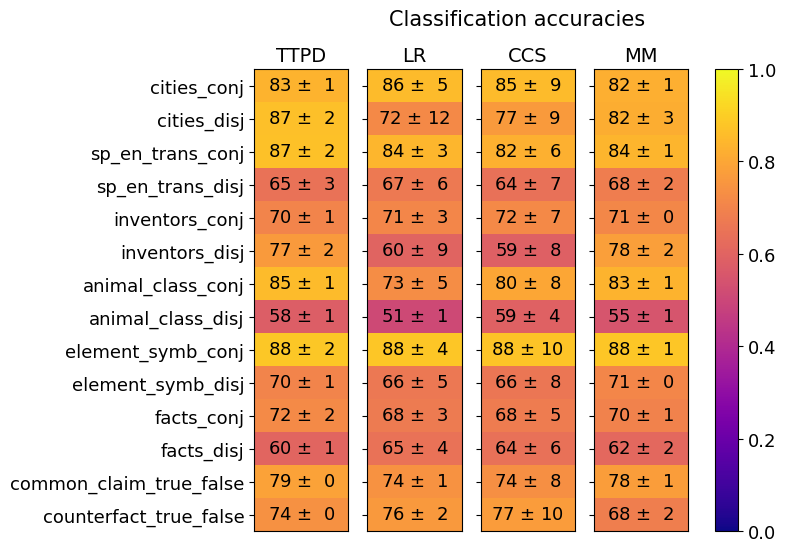
This image presents a heatmap displaying classification accuracies for various datasets and methods. The heatmap uses a color gradient from red (low accuracy) to green (high accuracy), with a scale from 0.0 to 1.0. The data is organized in a table format, with datasets listed on the y-axis and classification methods on the x-axis. Each cell represents the accuracy score (mean ± standard deviation) for a specific dataset-method combination.
### Components/Axes
* **Y-axis (Datasets):**
* cities_conj
* cities_disj
* sp_en_trans_conj
* sp_en_trans_disj
* inventors_conj
* inventors_disj
* animal_class_conj
* animal_class_disj
* element_symb_conj
* element_symb_disj
* facts_conj
* facts_disj
* common_claim_true_false
* counterfact_true_false
* **X-axis (Classification Methods):**
* TTPD
* LR
* CCS
* MM
* **Color Scale (Accuracy):**
* 0.0 (Dark Blue)
* 0.2 (Blue)
* 0.4 (Light Blue)
* 0.6 (Green)
* 0.8 (Yellow)
* 1.0 (Bright Yellow)
* **Title:** Classification accuracies
### Detailed Analysis
The heatmap displays accuracy scores with standard deviations. The values are presented as "mean ± standard deviation".
* **TTPD:**
* cities_conj: 83 ± 1
* cities_disj: 87 ± 2
* sp_en_trans_conj: 87 ± 2
* sp_en_trans_disj: 65 ± 3
* inventors_conj: 70 ± 1
* inventors_disj: 77 ± 2
* animal_class_conj: 85 ± 1
* animal_class_disj: 58 ± 1
* element_symb_conj: 88 ± 2
* element_symb_disj: 70 ± 1
* facts_conj: 72 ± 2
* facts_disj: 60 ± 1
* common_claim_true_false: 79 ± 0
* counterfact_true_false: 74 ± 0
* **LR:**
* cities_conj: 86 ± 5
* cities_disj: 72 ± 12
* sp_en_trans_conj: 84 ± 3
* sp_en_trans_disj: 67 ± 6
* inventors_conj: 71 ± 3
* inventors_disj: 60 ± 9
* animal_class_conj: 73 ± 5
* animal_class_disj: 51 ± 1
* element_symb_conj: 88 ± 4
* element_symb_disj: 66 ± 5
* facts_conj: 68 ± 5
* facts_disj: 65 ± 4
* common_claim_true_false: 74 ± 1
* counterfact_true_false: 76 ± 2
* **CCS:**
* cities_conj: 85 ± 9
* cities_disj: 77 ± 9
* sp_en_trans_conj: 82 ± 6
* sp_en_trans_disj: 64 ± 7
* inventors_conj: 72 ± 7
* inventors_disj: 59 ± 8
* animal_class_conj: 80 ± 8
* animal_class_disj: 59 ± 4
* element_symb_conj: 88 ± 10
* element_symb_disj: 66 ± 8
* facts_conj: 68 ± 5
* facts_disj: 64 ± 6
* common_claim_true_false: 74 ± 8
* counterfact_true_false: 77 ± 10
* **MM:**
* cities_conj: 82 ± 1
* cities_disj: 82 ± 3
* sp_en_trans_conj: 84 ± 1
* sp_en_trans_disj: 68 ± 2
* inventors_conj: 71 ± 0
* inventors_disj: 78 ± 2
* animal_class_conj: 83 ± 1
* animal_class_disj: 55 ± 1
* element_symb_conj: 88 ± 1
* element_symb_disj: 71 ± 0
* facts_conj: 70 ± 1
* facts_disj: 62 ± 2
* common_claim_true_false: 78 ± 1
* counterfact_true_false: 68 ± 2
### Key Observations
* The "element_symb_conj" dataset consistently achieves the highest accuracy across all methods, with values close to 1.0 (bright yellow).
* "animal_class_disj" and "sp_en_trans_disj" generally have lower accuracy scores (towards the blue end of the spectrum) compared to other datasets.
* TTPD and MM generally perform better than LR and CCS, especially on the "conj" datasets.
* The standard deviations are relatively small for most data points, indicating consistent results.
### Interpretation
The heatmap demonstrates the performance of four different classification methods (TTPD, LR, CCS, MM) on fourteen different datasets. The results suggest that the choice of method significantly impacts accuracy, and that certain datasets are more challenging to classify than others. The consistently high accuracy of TTPD and MM, particularly on the "conj" datasets, indicates their suitability for these types of tasks. The low accuracy on "animal_class_disj" and "sp_en_trans_disj" suggests that these datasets may require more sophisticated methods or feature engineering. The small standard deviations indicate that the results are reliable and not heavily influenced by random variation. The "conj" datasets generally perform better than the "disj" datasets, suggesting that the conjunctive nature of the data simplifies the classification task. The heatmap provides a clear visual comparison of method performance across datasets, enabling informed decisions about which method to use for a given task.