## Diagram: Privacy Preserving Text Classification
### Overview
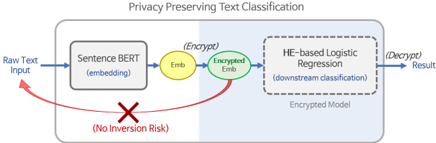
The image is a diagram illustrating a privacy-preserving text classification process. It shows the flow of data from raw text input to a final result, with encryption and decryption steps to ensure privacy. The diagram highlights the use of Sentence BERT for embedding and HE-based Logistic Regression for downstream classification, all within an encrypted model.
### Components/Axes
* **Title:** Privacy Preserving Text Classification
* **Input:** Raw Text Input
* **Component 1:** Sentence BERT (embedding)
* **Intermediate Data 1:** Emb (yellow circle)
* **Encryption Step:** (Encrypt)
* **Intermediate Data 2:** Encrypted Emb (green circle)
* **Component 2:** HE-based Logistic Regression (downstream classification)
* **Model Container:** Encrypted Model
* **Decryption Step:** (Decrypt)
* **Output:** Result
* **Privacy Note:** (No Inversion Risk)
### Detailed Analysis
The diagram depicts the following steps:
1. **Raw Text Input:** The process begins with raw text data.
2. **Sentence BERT (embedding):** The raw text is fed into a Sentence BERT model, which generates an embedding (Emb).
3. **Emb:** The embedding is represented by a yellow circle labeled "Emb".
4. **Encryption:** The embedding is then encrypted, indicated by "(Encrypt)".
5. **Encrypted Emb:** The encrypted embedding is represented by a green circle labeled "Encrypted Emb".
6. **HE-based Logistic Regression (downstream classification):** The encrypted embedding is processed by a Homomorphic Encryption (HE)-based Logistic Regression model for downstream classification. This model operates on encrypted data.
7. **Encrypted Model:** The HE-based Logistic Regression model is contained within a dashed-line box labeled "Encrypted Model".
8. **Decryption:** The output of the HE-based Logistic Regression model is decrypted, indicated by "(Decrypt)".
9. **Result:** The final result is obtained after decryption.
10. **Privacy Note:** A red arrow indicates a potential inversion risk from the "Raw Text Input" to the "Encrypted Emb", but this is crossed out with a red "X" and labeled "(No Inversion Risk)".
### Key Observations
* The diagram emphasizes the use of encryption to protect the privacy of the text data during the classification process.
* The use of HE-based Logistic Regression allows for computation on encrypted data without decryption.
* The diagram explicitly states that there is no inversion risk.
### Interpretation
The diagram illustrates a privacy-preserving text classification pipeline. The key idea is to perform the classification task on encrypted data, ensuring that the raw text data is never exposed during the process. The use of Sentence BERT for embedding and HE-based Logistic Regression for classification enables this privacy-preserving approach. The "No Inversion Risk" note suggests that the system is designed to prevent the recovery of the original text from the encrypted embedding. This is important for maintaining the privacy of the input data.