\n
## Diagram: Privacy Preserving Text Classification
### Overview
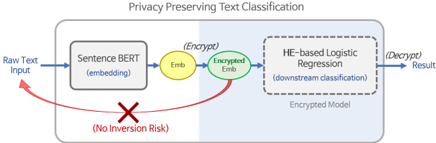
The image is a diagram illustrating a privacy-preserving text classification process. It depicts a flow of data from raw text input through several stages, including embedding, encryption, and classification, ultimately producing a decrypted result. The diagram emphasizes the prevention of inversion risk.
### Components/Axes
The diagram consists of the following components, arranged from left to right:
* **Raw Text Input:** The starting point of the process, indicated by a blue arrow labeled "Raw Text Input".
* **Sentence BERT (embedding):** A rectangular box labeled "Sentence BERT (embedding)".
* **Emb:** A yellow circle labeled "Emb".
* **(Encrypt):** A green oval labeled "(Encrypt)".
* **Encrypted Emb:** A circular shape labeled "Encrypted Emb".
* **HE-based Logistic Regression (downstream classification):** A dashed rectangular box labeled "HE-based Logistic Regression (downstream classification)".
* **Encrypted Model:** Text label below the HE-based Logistic Regression box.
* **(Decrypt) Result:** The final output, indicated by a blue arrow labeled "(Decrypt) Result".
* **No Inversion Risk:** A red "X" symbol within a red circle, labeled "No Inversion Risk".
* **Privacy Preserving Text Classification:** Title at the top of the diagram.
### Detailed Analysis or Content Details
The diagram illustrates a data flow:
1. Raw text input enters the "Sentence BERT (embedding)" stage.
2. The output of Sentence BERT is represented as "Emb".
3. "Emb" is then encrypted, becoming "Encrypted Emb".
4. "Encrypted Emb" is fed into "HE-based Logistic Regression (downstream classification)".
5. The output of the Logistic Regression is decrypted to produce the final "Result".
6. A red curved arrow originates from "Raw Text Input" and points towards "Encrypted Emb", with a red "X" symbol indicating "No Inversion Risk". This suggests that the raw text cannot be recovered from the encrypted embedding.
### Key Observations
The diagram highlights the use of Homomorphic Encryption (HE) to enable classification on encrypted data, thus preserving privacy. The "No Inversion Risk" indicator is a key feature, emphasizing the security of the process. The diagram is a high-level overview and does not provide specific details about the encryption scheme or the classification model.
### Interpretation
This diagram demonstrates a system designed for privacy-preserving text classification. The core idea is to perform the classification task on encrypted data, preventing unauthorized access to the original text. The use of Sentence BERT for embedding suggests a semantic understanding of the text, while HE-based Logistic Regression allows for classification without decrypting the data. The "No Inversion Risk" indicator is crucial, as it assures that even with access to the encrypted embedding, the original text cannot be reconstructed. This approach is particularly relevant in scenarios where data privacy is paramount, such as healthcare or finance. The diagram is a conceptual illustration and does not provide quantitative data or performance metrics. It focuses on the overall architecture and the key privacy-preserving features of the system.