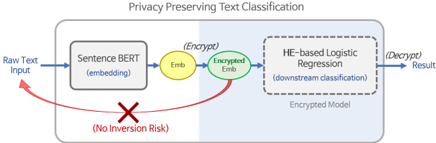
\n
## Diagram: Privacy Preserving Text Classification Process Flow
### Overview
The image is a technical process flow diagram illustrating a system for "Privacy Preserving Text Classification." It depicts a pipeline where raw text is transformed into an encrypted embedding for classification by a downstream model, with a specific security feature highlighted to prevent data inversion attacks.
### Components/Axes
The diagram is structured as a left-to-right flowchart contained within a light gray rounded rectangle. Key components are:
1. **Title:** "Privacy Preserving Text Classification" (centered at the top).
2. **Input:** "Raw Text Input" (text label on the far left).
3. **Process Block 1 (Left):** A light blue rectangle labeled "Sentence BERT (embedding)".
4. **Intermediate Data:**
* A yellow oval labeled "Emb." (abbreviation for Embedding).
* A green oval labeled "Encrypted Text".
5. **Process Block 2 (Right):** A dashed-line rectangle labeled "NE-based Logistic Regression (downstream classification)". Below this label, inside the box, is the text "Encrypted Model".
6. **Output:** "(Decrypt) Results" (text label on the far right).
7. **Security Annotation:** A prominent red curved arrow originates from the "Encrypted Text" oval, points back towards the "Raw Text Input," and is crossed out with a red "X". Below this arrow is the red text "(No Inversion Risk)".
### Detailed Analysis
The process flow is as follows:
1. **Input Stage:** The process begins with "Raw Text Input" on the left.
2. **Embedding Stage:** The raw text is fed into the "Sentence BERT (embedding)" model. The output of this model is an embedding, represented by the yellow "Emb." oval.
3. **Encryption Stage:** The embedding is then transformed into "Encrypted Text," represented by the green oval. This is the critical privacy-preserving step.
4. **Classification Stage:** The "Encrypted Text" is passed to the "NE-based Logistic Regression" model, which is explicitly noted as an "Encrypted Model." This model performs the downstream classification task on the encrypted data.
5. **Output Stage:** The final output is labeled "(Decrypt) Results," indicating that the classification results are decrypted for the end-user.
6. **Security Feature:** The red annotation is a key part of the diagram. It visually asserts that the encryption applied to the text embedding creates a barrier, making it impossible to invert the process and recover the original "Raw Text Input" from the "Encrypted Text." The red "X" over the arrow explicitly negates the possibility of this inversion attack.
### Key Observations
* **Dual-Stage Processing:** The system uses two distinct models: a Sentence BERT model for creating embeddings and a specialized NE-based Logistic Regression model for classification on encrypted data.
* **Encryption Point:** Encryption is applied *after* the initial embedding by Sentence BERT, not to the raw text itself. The diagram labels the encrypted data as "Encrypted Text," but it is derived from the embedding ("Emb.").
* **Visual Security Guarantee:** The most prominent visual element is the red "No Inversion Risk" annotation, which is the diagram's central claim about the system's privacy properties.
* **Model State:** The downstream classifier is specifically described as an "Encrypted Model," suggesting it may be designed to operate directly on ciphertext or encrypted representations.
### Interpretation
This diagram illustrates a machine learning pipeline designed to address a core privacy concern: performing useful analysis (text classification) on sensitive data without exposing the original information.
The data suggests a method where the raw text is immediately transformed into a mathematical representation (embedding) and then encrypted. The core innovation or claim is that this encryption is robust enough to prevent "inversion attacks"—where an adversary might try to reconstruct the original input from the model's internal representations or outputs. The red "X" is a strong, non-technical symbol meant to communicate this security guarantee to a viewer.
The relationship between components shows a clear separation of duties: one model (Sentence BERT) handles feature extraction, while a second, specialized model (NE-based Logistic Regression) operates in the encrypted domain. This implies the second model is either homomorphically compatible or uses another form of secure computation. The "(Decrypt) Results" at the end indicates that while processing is done on encrypted data, the final actionable output is made available in a readable format.
The notable anomaly or point of interest is the labeling of the encrypted data as "Encrypted Text." Technically, it is an encrypted *embedding*, not the text itself. This might be a simplification for the diagram, but it's an important distinction for understanding the actual data transformation. The diagram's primary purpose is to advocate for the system's security ("No Inversion Risk") while showing a functional workflow from raw input to decrypted results.