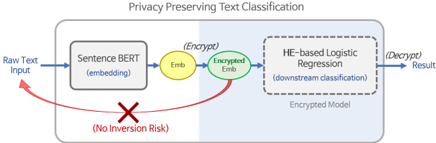
## Diagram: Privacy Preserving Text Classification
### Overview
This diagram illustrates a privacy-preserving text classification pipeline using homomorphic encryption (HE) and Sentence BERT embeddings. The process ensures raw text data remains secure while enabling downstream classification tasks.
### Components/Axes
1. **Blocks**:
- **Raw Text Input**: Starting point for the pipeline.
- **Sentence BERT (embedding)**: Converts raw text into embeddings.
- **Encrypt**: Encrypts embeddings using homomorphic encryption.
- **Encrypted Emb**: Encrypted version of the embeddings.
- **HE-based Logistic Regression (downstream classification)**: Performs classification on encrypted data.
- **Decrypt**: Decrypts the classification result.
- **Result**: Final output of the classification task.
- **No Inversion Risk**: Red arrow with a cross symbol indicating that encrypted embeddings cannot be reverse-engineered to raw text.
2. **Arrows**:
- Blue arrows indicate the primary data flow.
- Red arrow with a cross symbolizes the prevention of inversion risk.
### Detailed Analysis
- **Raw Text Input** → **Sentence BERT (embedding)**: Raw text is processed into embeddings using Sentence BERT, a transformer-based model for semantic understanding.
- **Encrypt** → **Encrypted Emb**: Embeddings are encrypted using homomorphic encryption (HE), allowing computations on encrypted data without decryption.
- **Encrypted Emb** → **HE-based Logistic Regression**: Classification is performed directly on encrypted embeddings, preserving privacy.
- **HE-based Logistic Regression** → **Decrypt** → **Result**: The classification result is decrypted and returned as the final output.
- **No Inversion Risk**: The red arrow with a cross explicitly states that the encrypted embeddings cannot be inverted back to raw text, ensuring data confidentiality.
### Key Observations
1. **Privacy Preservation**: The pipeline avoids exposing raw text or unencrypted embeddings at any stage.
2. **Homomorphic Encryption (HE)**: Enables secure computation on encrypted data, critical for privacy-sensitive applications.
3. **No Inversion Risk**: The explicit warning highlights the system’s design to prevent reverse-engineering of sensitive data from encrypted outputs.
### Interpretation
This diagram demonstrates a secure text classification framework where:
- **Sentence BERT** provides semantic embeddings for text.
- **Homomorphic Encryption** ensures data remains encrypted during processing, preventing exposure of sensitive information.
- **HE-based Logistic Regression** allows classification without decrypting the data, maintaining privacy.
- The **No Inversion Risk** annotation emphasizes the system’s robustness against data leakage via encrypted embeddings.
The pipeline balances utility (via HE-compatible computations) and privacy (via encryption and inversion resistance), making it suitable for applications requiring strict data confidentiality.