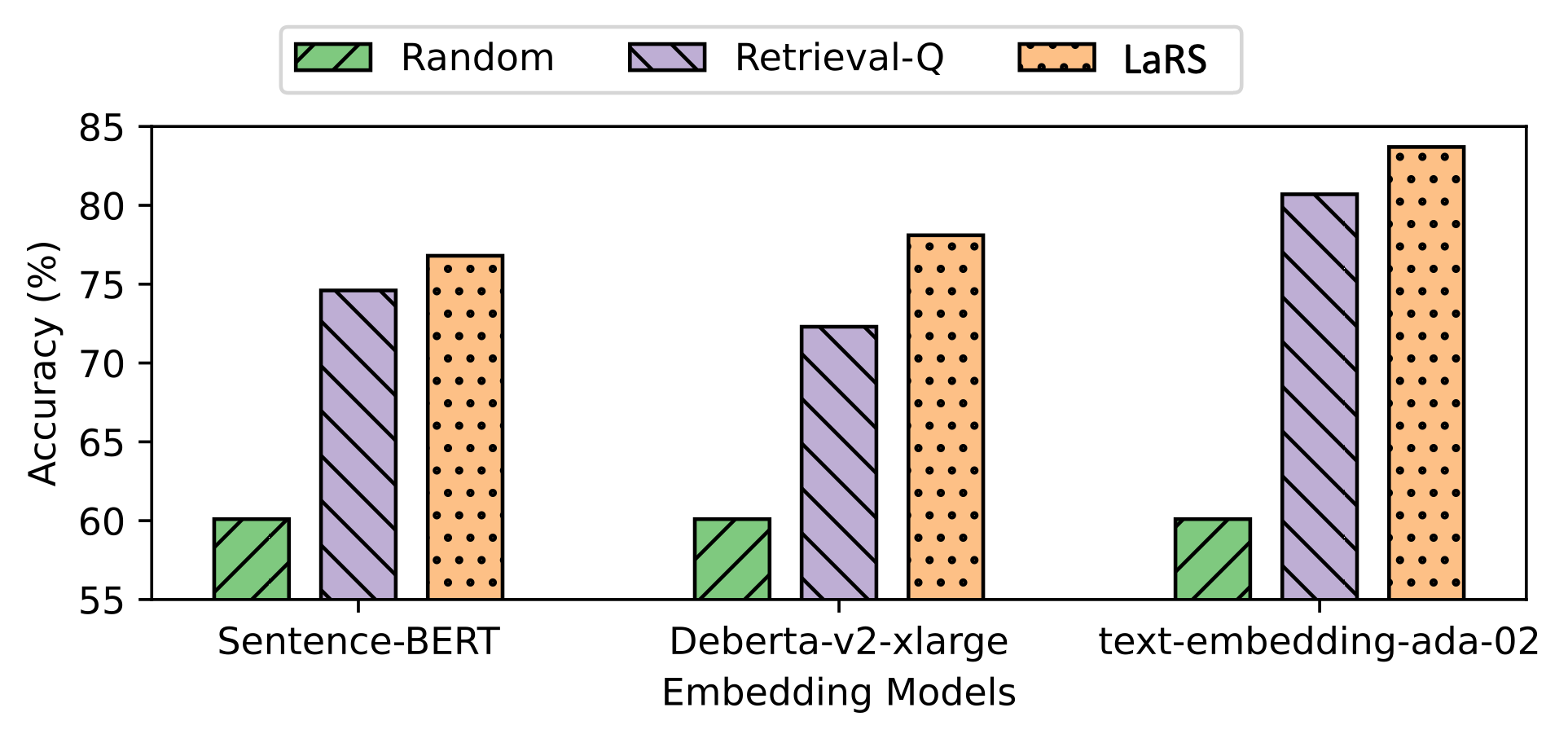
## Grouped Bar Chart: Accuracy Comparison of Retrieval Methods Across Embedding Models
### Overview
The image is a grouped bar chart comparing the accuracy (in percentage) of three different retrieval or selection methods ("Random", "Retrieval-Q", and "LaRS") when applied to three distinct text embedding models. The chart visually demonstrates the performance hierarchy of the methods and the relative effectiveness of the underlying embedding models.
### Components/Axes
* **Chart Type:** Grouped Bar Chart.
* **Y-Axis (Vertical):**
* **Label:** "Accuracy (%)"
* **Scale:** Linear scale ranging from 55 to 85, with major tick marks at intervals of 5 (55, 60, 65, 70, 75, 80, 85).
* **X-Axis (Horizontal):**
* **Label:** "Embedding Models"
* **Categories (from left to right):**
1. Sentence-BERT
2. Deberta-v2-xlarge
3. text-embedding-ada-02
* **Legend (Top Center):**
* **Random:** Represented by a green bar with a diagonal line pattern (\\).
* **Retrieval-Q:** Represented by a light purple bar with a diagonal line pattern (\\).
* **LaRS:** Represented by an orange bar with a black dot pattern (•).
### Detailed Analysis
The chart presents accuracy data for nine distinct scenarios (3 methods x 3 models). Values are approximate, estimated from the bar heights relative to the y-axis.
**1. For the "Sentence-BERT" embedding model (leftmost group):**
* **Random (Green, \\):** Accuracy is approximately **60%**.
* **Retrieval-Q (Purple, \\):** Accuracy is approximately **75%**.
* **LaRS (Orange, •):** Accuracy is approximately **77%**.
* *Trend:* LaRS performs best, followed closely by Retrieval-Q. Both significantly outperform the Random baseline.
**2. For the "Deberta-v2-xlarge" embedding model (center group):**
* **Random (Green, \\):** Accuracy is approximately **60%**.
* **Retrieval-Q (Purple, \\):** Accuracy is approximately **72%**.
* **LaRS (Orange, •):** Accuracy is approximately **78%**.
* *Trend:* LaRS again performs best, with a more pronounced lead over Retrieval-Q compared to the first model. The Random baseline remains consistent.
**3. For the "text-embedding-ada-02" embedding model (rightmost group):**
* **Random (Green, \\):** Accuracy is approximately **60%**.
* **Retrieval-Q (Purple, \\):** Accuracy is approximately **81%**.
* **LaRS (Orange, •):** Accuracy is approximately **84%**.
* *Trend:* This model yields the highest overall accuracies for the non-random methods. LaRS achieves the peak performance on the chart, with Retrieval-Q also showing a strong result. The Random baseline is unchanged.
### Key Observations
1. **Consistent Baseline:** The "Random" method's accuracy is remarkably stable at approximately 60% across all three embedding models, serving as a fixed performance baseline.
2. **Method Hierarchy:** A clear and consistent performance hierarchy exists across all models: **LaRS > Retrieval-Q > Random**. LaRS is always the top-performing method.
3. **Model Impact:** The choice of embedding model significantly impacts the accuracy of the intelligent methods (Retrieval-Q and LaRS). Performance improves from Sentence-BERT to Deberta-v2-xlarge to text-embedding-ada-02 for these methods.
4. **Peak Performance:** The highest accuracy on the chart (~84%) is achieved by the **LaRS** method when used with the **text-embedding-ada-02** embedding model.
5. **Visual Patterns:** The chart uses distinct colors (green, purple, orange) and fill patterns (diagonal lines, dots) to ensure clear differentiation between the methods, even if printed in grayscale.
### Interpretation
This chart provides strong evidence for the effectiveness of the **LaRS** method over both a **Retrieval-Q** approach and a random baseline in a retrieval or selection task. The data suggests that LaRS is a robust technique that consistently extracts better performance from various underlying text representation models.
The significant variance in accuracy for LaRS and Retrieval-Q across the three embedding models (from ~72% to ~84%) indicates that the quality of the base embeddings is a critical factor for success. The **text-embedding-ada-02** model appears to provide the most informative representations for this specific task, as it enables the highest accuracies for both intelligent methods.
The flat performance of the "Random" baseline is an important control. It confirms that the improvements seen with Retrieval-Q and LaRS are due to their intelligent mechanisms and not artifacts of the test set or embedding models themselves. The chart effectively argues for adopting LaRS, particularly when paired with a high-performing embedding model like text-embedding-ada-02, to maximize task accuracy.