# Technical Diagram Analysis: Token Sequence Generation
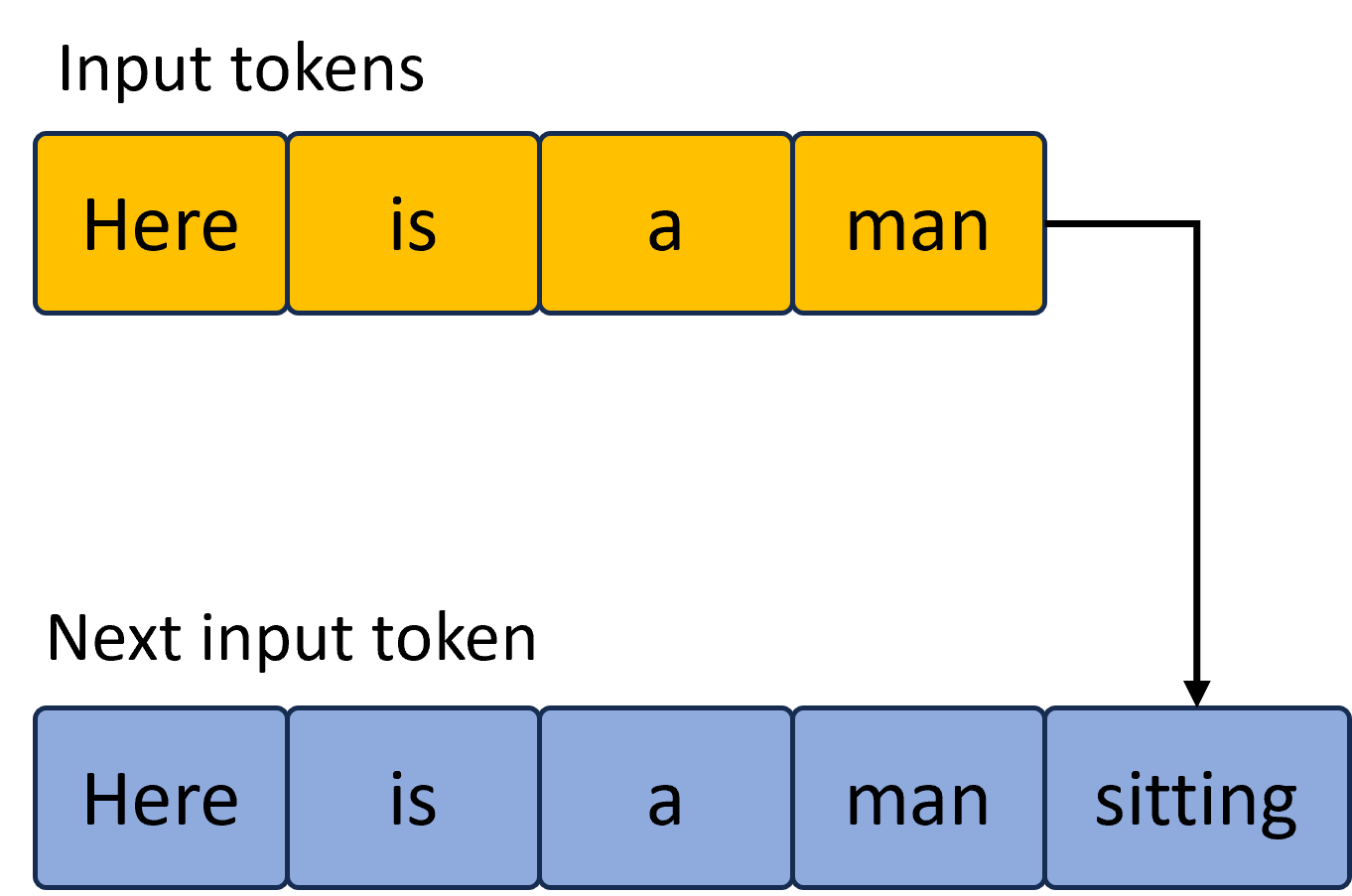
This image illustrates the process of autoregressive token generation in a Large Language Model (LLM). It shows how a sequence of input tokens is processed to predict and append the subsequent token.
## 1. Component Isolation
### Header Region: Input Tokens
* **Label:** "Input tokens" (Top-left)
* **Visual Representation:** A horizontal sequence of four yellow rectangular blocks with dark blue borders.
* **Content (Left to Right):**
1. `Here`
2. `is`
3. `a`
4. `man`
### Footer Region: Next Input Token
* **Label:** "Next input token" (Middle-left, above the second sequence)
* **Visual Representation:** A horizontal sequence of five light blue rectangular blocks with dark blue borders.
* **Content (Left to Right):**
1. `Here`
2. `is`
3. `a`
4. `man`
5. `sitting`
## 2. Flow and Logic Description
The diagram uses a black directional arrow to indicate the transition from the initial state to the updated state.
* **Origin:** The arrow originates from the right side of the final yellow block (`man`) in the "Input tokens" sequence.
* **Path:** The arrow moves horizontally to the right, then turns 90 degrees downward, ending with an arrowhead pointing at the fifth block (`sitting`) in the "Next input token" sequence.
* **Logic:** This indicates that the word "sitting" has been generated based on the context of the previous four tokens. The new sequence (blue) now includes the original context plus the newly predicted token, which will serve as the input for the next generation step.
## 3. Text Transcription Summary
| Category | Sequence Content |
| :--- | :--- |
| **Input tokens** | Here, is, a, man |
| **Next input token** | Here, is, a, man, sitting |
## 4. Visual Attributes
* **Color Coding:**
* **Yellow:** Represents the initial context/input state.
* **Light Blue:** Represents the updated state/output sequence.
* **Background:** Light gray.
* **Font:** Sans-serif, black text.