# Technical Document Extraction: Diagram Analysis
## Diagram Overview
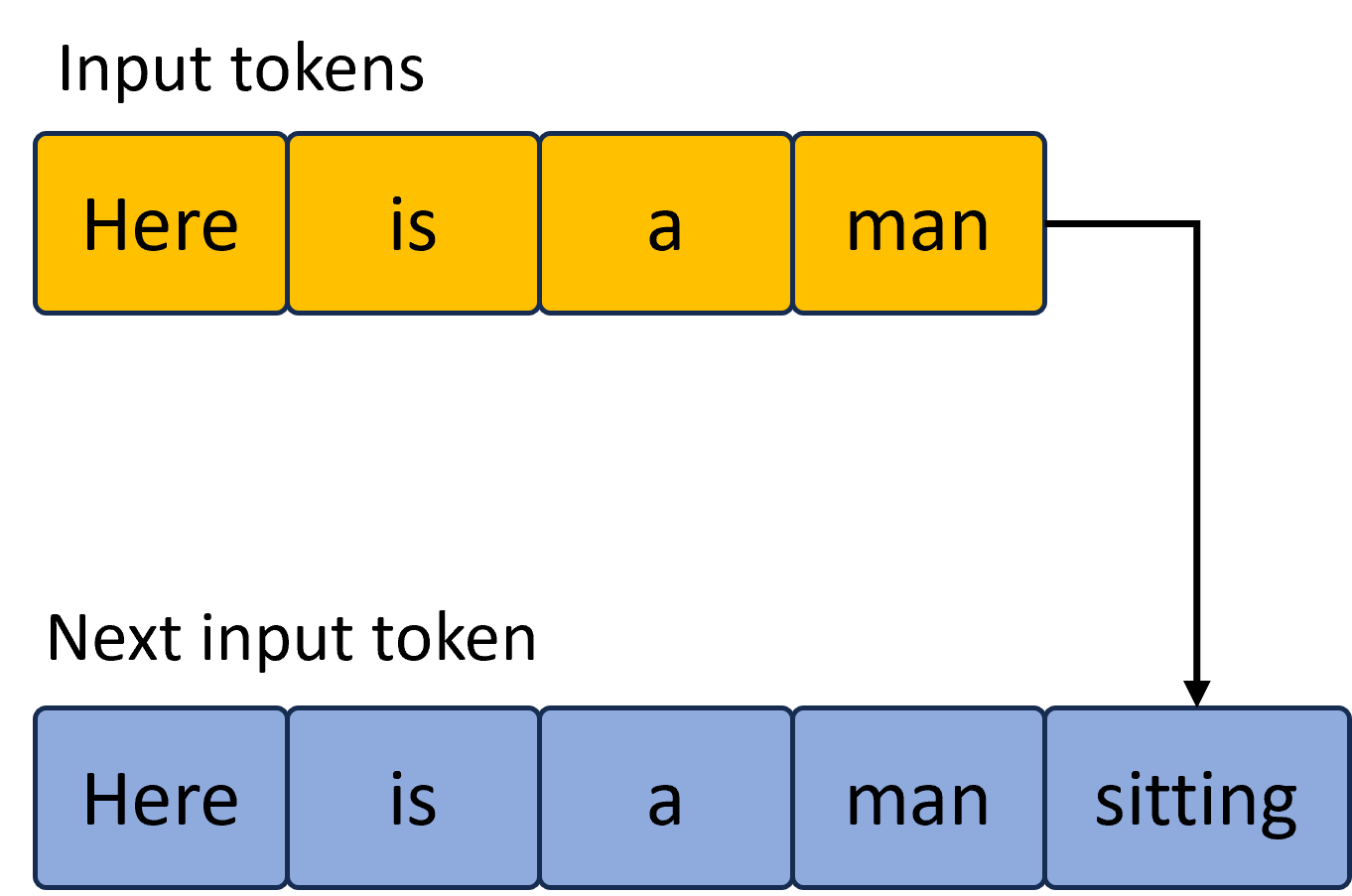
The image depicts a sequential token processing diagram with two distinct sections:
### Section 1: Input Tokens
- **Label**: "Input tokens" (top-left header)
- **Components**:
- Four horizontally aligned orange boxes with black text:
1. "Here" (x=0, y=0)
2. "is" (x=1, y=0)
3. "a" (x=2, y=0)
4. "man" (x=3, y=0)
- **Connectivity**:
- Black arrow originating from "man" box (x=3, y=0)
- Arrow direction: Downward-right to Section 2
### Section 2: Next Input Token
- **Label**: "Next input token" (bottom-left header)
- **Components**:
- Five horizontally aligned blue boxes with black text:
1. "Here" (x=0, y=1)
2. "is" (x=1, y=1)
3. "a" (x=2, y=1)
4. "man" (x=3, y=1)
5. "sitting" (x=4, y=1)
- **Connectivity**:
- Black arrow terminates at "sitting" box (x=4, y=1)
## Key Observations
1. **Color Coding**:
- Input tokens: Orange (#FFA500)
- Next input tokens: Blue (#87CEEB)
- No explicit legend present
2. **Spatial Grounding**:
- All boxes share uniform width/height
- Horizontal alignment maintained across both sections
- Vertical separation between sections (y=0 vs y=1)
3. **Temporal Flow**:
- Arrow establishes causal relationship:
`Input tokens → Next input token`
- Indicates sequential processing of tokens
4. **Textual Content**:
- Input sequence: ["Here", "is", "a", "man"]
- Extended sequence: ["Here", "is", "a", "man", "sitting"]
- No repeated tokens within individual sections
## Structural Analysis