## Diagram: Training Stages for Knowledge Graph Empowerment, Enhancement, and Generalization
### Overview
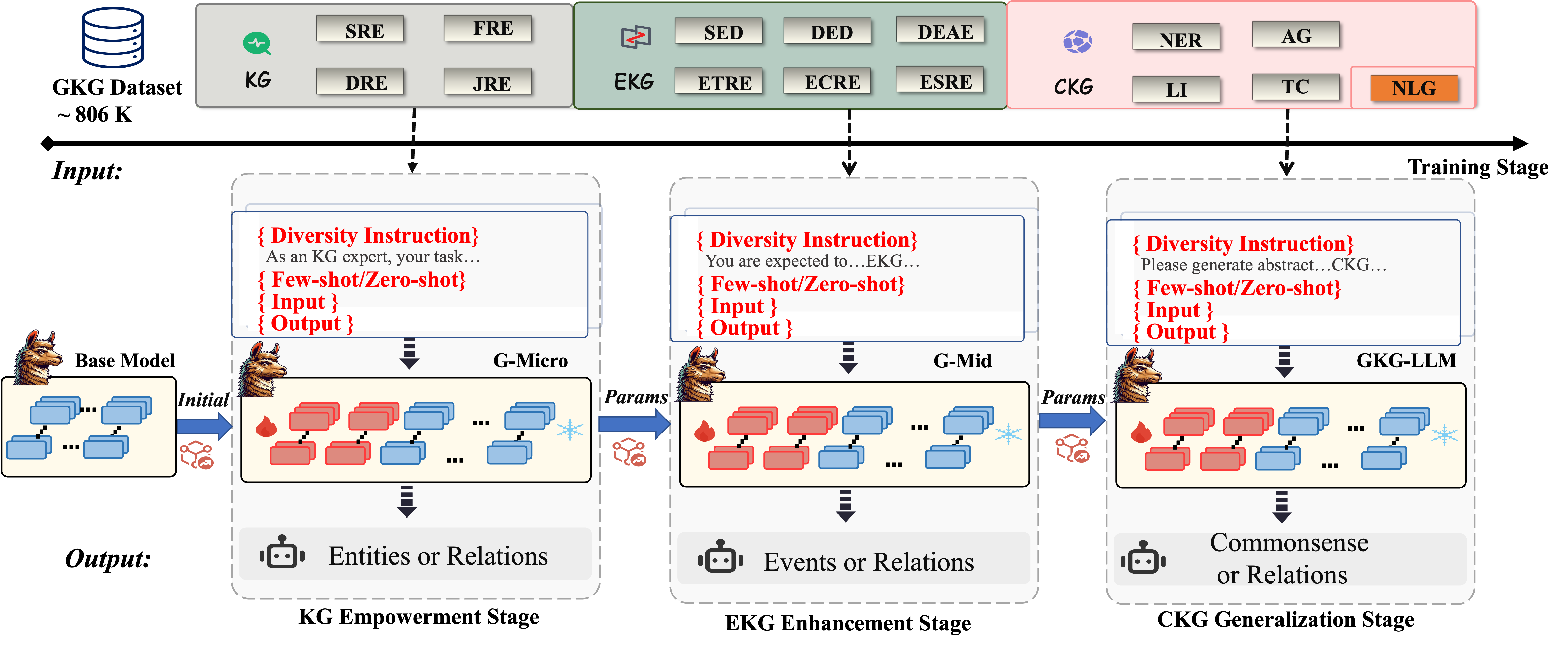
The image is a diagram illustrating a multi-stage training process involving Knowledge Graphs (KG), Event Knowledge Graphs (EKG), and Commonsense Knowledge Graphs (CKG). The process uses a base model and progresses through three stages: KG Empowerment, EKG Enhancement, and CKG Generalization. Each stage involves diversity instruction, few-shot/zero-shot learning, input, and output.
### Components/Axes
* **Header:** Contains labels for different knowledge graph types and tasks.
* **KG (Knowledge Graph):** Includes SRE (Semantic Relation Extraction), DRE (Domain Relation Extraction).
* **EKG (Event Knowledge Graph):** Includes SED (Semantic Event Detection), ETRE (Event Temporal Relation Extraction), ECRE (Event Cause Relation Extraction), ESRE (Event Spatial Relation Extraction), DED (Domain Event Detection), DEAE (Domain Event Argument Extraction).
* **CKG (Commonsense Knowledge Graph):** Includes NER (Named Entity Recognition), LI (Linguistic Inference), AG (Argument Generation), TC (Textual Completion), NLG (Natural Language Generation).
* **Main Body:** Illustrates the three training stages.
* **Input:** Indicates the GKG Dataset of approximately 806K.
* **Training Stage:** A horizontal arrow indicating the progression of the training process.
* **KG Empowerment Stage:** Involves a "Base Model" and "G-Micro" model. The input is "Entities or Relations".
* **EKG Enhancement Stage:** Involves a "G-Mid" model. The input is "Events or Relations".
* **CKG Generalization Stage:** Involves a "GKG-LLM" model. The input is "Commonsense or Relations".
* **Footer:** Labels the output of each stage.
* **Output:** Indicates the type of output generated at each stage.
### Detailed Analysis
1. **Data Source:** The training process uses a "GKG Dataset" of approximately 806K.
2. **Training Stages:**
* **KG Empowerment Stage:**
* Starts with a "Base Model" represented by blue blocks.
* Transitions to a "G-Micro" model, where the blocks are a mix of red and blue, indicating a transformation or enhancement.
* The process is guided by "{ Diversity Instruction} As an KG expert, your task... {Few-shot/Zero-shot} { Input } { Output }".
* The output is "Entities or Relations".
* **EKG Enhancement Stage:**
* The "G-Micro" model transitions to a "G-Mid" model, again with a mix of red and blue blocks.
* The process is guided by "{ Diversity Instruction} You are expected to...EKG... { Few-shot/Zero-shot} { Input } { Output }".
* The output is "Events or Relations".
* **CKG Generalization Stage:**
* The "G-Mid" model transitions to a "GKG-LLM" model, with a mix of red and blue blocks.
* The process is guided by "{ Diversity Instruction} Please generate abstract...CKG... { Few-shot/Zero-shot} { Input } { Output }".
* The output is "Commonsense or Relations".
3. **Model Progression:** The models progress from "Base Model" to "G-Micro", "G-Mid", and finally "GKG-LLM". The transition between models is indicated by arrows labeled "Initial" and "Params".
4. **Visual Representation:** The blue blocks likely represent initial data or states, while the red blocks represent transformed or enhanced data/states. The snowflake icon may represent a cooling or refinement process. The flame icon may represent a heating or intensification process.
### Key Observations
* The diagram illustrates a pipeline for training models to handle different types of knowledge graphs.
* Each stage focuses on a specific type of knowledge graph: KG, EKG, and CKG.
* The models are progressively enhanced through the stages, as indicated by the transition from "Base Model" to "G-Micro", "G-Mid", and "GKG-LLM".
* The use of "Diversity Instruction" and "Few-shot/Zero-shot" learning suggests a focus on improving the model's ability to generalize and adapt to new data.
### Interpretation
The diagram presents a structured approach to training models for knowledge graph tasks. The progression from KG to EKG to CKG suggests an increasing level of complexity and abstraction. The use of diversity instruction and few-shot/zero-shot learning indicates a focus on building models that can handle a wide range of tasks with limited data. The visual representation of the models and data transformations provides a high-level overview of the training process. The diagram highlights the importance of each stage in building a comprehensive knowledge graph system.