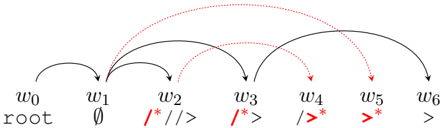
## Diagram: State Transition Diagram with Token/State Labels
### Overview
The image displays a directed graph diagram representing a sequence of states or nodes (labeled `w0` through `w6`) connected by two distinct types of arrows: solid black lines and dashed red lines. Each node has an associated label or symbol beneath it, suggesting a progression from an initial "root" state through various intermediate states, potentially representing parsing states, token types, or symbolic transformations in a formal system (e.g., compiler design, formal grammar, or automata theory).
### Components/Axes
* **Nodes (States):** Seven nodes arranged horizontally in a linear sequence from left to right.
* **Node Labels (Top):** `w0`, `w1`, `w2`, `w3`, `w4`, `w5`, `w6`
* **Node Descriptions (Bottom):**
* `w0`: `root`
* `w1`: `∅` (the empty set symbol)
* `w2`: `/ // >`
* `w3`: `/* >`
* `w4`: `/ *`
* `w5`: `> *`
* `w6`: `>`
* **Edges (Transitions):**
* **Solid Black Arrows:** Indicate one type of transition or relationship.
* **Dashed Red Arrows:** Indicate a second, distinct type of transition or relationship.
* **Spatial Grounding of Connections:**
* From `w0` (root): A single solid black arrow points to `w1`.
* From `w1` (∅): Solid black arrows point to **all subsequent nodes** (`w2`, `w3`, `w4`, `w5`, `w6`). Dashed red arrows also point from `w1` to **all subsequent nodes** (`w2`, `w3`, `w4`, `w5`, `w6`).
* Between subsequent nodes (`w2` through `w6`): Each node has a solid black arrow pointing to the **immediately following node** (e.g., `w2` -> `w3`, `w3` -> `w4`). Each node also has a dashed red arrow pointing to the **immediately following node**.
### Detailed Analysis
* **Node Sequence & Labels:** The diagram depicts a clear left-to-right progression. The labels evolve from a generic "root" and "empty set" (`∅`) to increasingly specific symbolic strings involving slashes (`/`), asterisks (`*`), and greater-than signs (`>`). The strings appear to be fragments or tokens, possibly representing comment delimiters (`//`, `/*`, `*/`) or operators in a programming language.
* **Transition Patterns:**
1. **Initial Step:** The process begins at `w0` (root) and unconditionally moves to `w1` (empty set) via a solid black arrow.
2. **Branching from `w1`:** The state `w1` acts as a major branching point. It has **dual outgoing connections** (both solid black and dashed red) to every subsequent state (`w2` through `w6`). This suggests that from the "empty set" state, multiple paths or interpretations are possible.
3. **Linear Chain:** From `w2` onward, the nodes form a simple linear chain. Each node connects only to its immediate successor, and each connection is represented by **both a solid black and a dashed red arrow**. This indicates that the relationship between consecutive states in this chain is characterized by two parallel or alternative aspects.
### Key Observations
* **Dual Transition Types:** The consistent use of two arrow styles (solid black, dashed red) between the same pairs of nodes is the most prominent feature. This implies a fundamental duality in the system being modeled—such as expected vs. actual transitions, syntactic vs. semantic relationships, or primary vs. secondary derivation rules.
* **`w1` as a Hub:** Node `w1` (∅) is uniquely positioned as the sole source of transitions to all other non-root nodes. Its label, the empty set, may symbolize a starting point of no content, from which all possible token sequences can be generated or parsed.
* **Symbolic Progression:** The labels from `w2` to `w6` (`/ // >`, `/* >`, `/ *`, `> *`, `>`) do not follow an obvious alphabetical or numerical order. Their sequence may represent the step-by-step construction or deconstruction of a complex token (like a block comment `/* ... */`) or the states of a parser recognizing such tokens.
### Interpretation
This diagram likely models the **state transitions of a lexical analyzer (lexer) or parser** for a language with specific comment syntax. The nodes `w0` to `w6` represent parser states, and the labels beneath them represent the **type of token or syntactic element** recognized upon entering that state.
* **`w0` (root)** is the initial state.
* **`w1` (∅)** represents a state where no significant token has been recognized yet (the "empty" state after consuming whitespace or in between tokens).
* The **solid black arrows** could represent **expected or valid state transitions** based on the language's grammar rules.
* The **dashed red arrows** could represent **alternative transitions**, perhaps for error recovery, fallback parsing rules, or transitions triggered by different input conditions.
* The progression from `w2` to `w6` may trace the recognition of a comment:
* `w2` (`/ // >`): Possibly a state after seeing a `/`, with potential paths to form `//` (line comment) or `/*` (block comment start).
* `w3` (`/* >`): State after recognizing the start of a block comment `/*`.
* `w4` (` / *`): A state within the comment body, perhaps after seeing a `*` that could potentially end the comment.
* `w5` (`> *`): A state where a `*` has been seen, and the next `/` would complete the comment end `*/`.
* `w6` (`>`): The final state after the comment has been fully recognized and closed.
The diagram's core message is the **dual-path nature of the parsing process** from the empty state and the **linear, deterministic progression** once a specific token sequence (like a comment) has begun. It visually separates the initial, highly non-deterministic choice of what token to parse next from the subsequent, more constrained steps of completing that token's syntax.