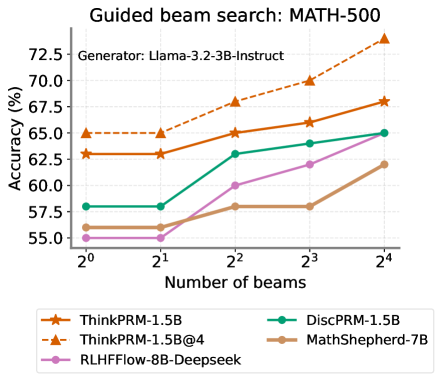
## Line Chart: Guided Beam Search - MATH-500 Accuracy
### Overview
This line chart illustrates the relationship between the number of beams used in a guided beam search and the resulting accuracy on the MATH-500 dataset. The chart compares the performance of several different models: ThinkPRM-1.5B, ThinkPRM-1.5B@4, DiscPRM-1.5B, MathShepherd-7B, and RLHFflow-8B-Deepseek. The generator used for all models is Llama-3.2-3B-Instruct.
### Components/Axes
* **Title:** "Guided beam search: MATH-500"
* **Subtitle:** "Generator: Llama-3.2-3B-Instruct" (positioned centrally below the title)
* **X-axis:** "Number of beams" with markers at 2⁰, 2¹, 2², 2³, and 2⁴.
* **Y-axis:** "Accuracy (%)" with a scale ranging from approximately 55.0% to 72.5%.
* **Legend:** Located at the bottom of the chart, horizontally aligned. It contains the following labels and corresponding colors:
* ThinkPRM-1.5B (Orange)
* ThinkPRM-1.5B@4 (Dark Orange, dashed line)
* DiscPRM-1.5B (Teal)
* MathShepherd-7B (Gray)
* RLHFflow-8B-Deepseek (Purple)
### Detailed Analysis
The chart displays five distinct lines, each representing a different model's accuracy as the number of beams increases.
* **ThinkPRM-1.5B (Orange):** The line slopes upward consistently.
* At 2⁰ beams: Approximately 62.2% accuracy.
* At 2¹ beams: Approximately 63.5% accuracy.
* At 2² beams: Approximately 65.0% accuracy.
* At 2³ beams: Approximately 67.0% accuracy.
* At 2⁴ beams: Approximately 68.2% accuracy.
* **ThinkPRM-1.5B@4 (Dark Orange, dashed):** This line shows the most significant upward trend.
* At 2⁰ beams: Approximately 65.0% accuracy.
* At 2¹ beams: Approximately 66.5% accuracy.
* At 2² beams: Approximately 68.5% accuracy.
* At 2³ beams: Approximately 70.0% accuracy.
* At 2⁴ beams: Approximately 72.5% accuracy.
* **DiscPRM-1.5B (Teal):** The line shows a moderate upward trend, with a slight flattening at the higher beam counts.
* At 2⁰ beams: Approximately 57.5% accuracy.
* At 2¹ beams: Approximately 58.5% accuracy.
* At 2² beams: Approximately 62.0% accuracy.
* At 2³ beams: Approximately 63.0% accuracy.
* At 2⁴ beams: Approximately 63.5% accuracy.
* **MathShepherd-7B (Gray):** The line shows a relatively flat trend, with a slight increase.
* At 2⁰ beams: Approximately 55.0% accuracy.
* At 2¹ beams: Approximately 56.0% accuracy.
* At 2² beams: Approximately 57.5% accuracy.
* At 2³ beams: Approximately 57.5% accuracy.
* At 2⁴ beams: Approximately 61.0% accuracy.
* **RLHFflow-8B-Deepseek (Purple):** The line shows an upward trend, but less pronounced than ThinkPRM-1.5B@4.
* At 2⁰ beams: Approximately 55.5% accuracy.
* At 2¹ beams: Approximately 57.0% accuracy.
* At 2² beams: Approximately 58.5% accuracy.
* At 2³ beams: Approximately 60.5% accuracy.
* At 2⁴ beams: Approximately 62.5% accuracy.
### Key Observations
* ThinkPRM-1.5B@4 consistently outperforms all other models across all beam counts.
* The performance gap between ThinkPRM-1.5B@4 and the other models widens as the number of beams increases.
* MathShepherd-7B exhibits the lowest overall accuracy and the flattest trend.
* Increasing the number of beams generally improves accuracy for all models, but the rate of improvement varies.
### Interpretation
The data suggests that guided beam search is an effective technique for improving the accuracy of language models on the MATH-500 dataset. The model ThinkPRM-1.5B@4, in particular, demonstrates a strong ability to leverage the benefits of increasing the number of beams. The relatively poor performance of MathShepherd-7B may indicate that it is less well-suited to this particular task or that it requires different optimization strategies. The consistent upward trends across most models suggest that there is still potential for further accuracy gains by exploring even larger beam counts. The difference in performance between ThinkPRM-1.5B and ThinkPRM-1.5B@4 suggests that the "@4" modification significantly improves the model's ability to utilize beam search. The use of Llama-3.2-3B-Instruct as the generator provides a common baseline for comparing the performance of these different models.