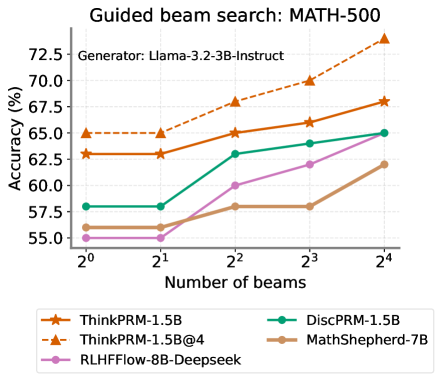
## Line Chart: Guided beam search: MATH-500
### Overview
The chart compares the accuracy of five different models (ThinkPRM-1.5B, DiscPRM-1.5B, ThinkPRM-1.5B@4, MathShepherd-7B, RLHFFlow-8B-Deepseek) across varying numbers of beams (2⁰ to 2⁴) in a guided beam search task on the MATH-500 dataset. Accuracy is measured in percentage, with the y-axis ranging from 55% to 72.5%.
### Components/Axes
- **X-axis**: "Number of beams" (logarithmic scale: 2⁰, 2¹, 2², 2³, 2⁴ → 1, 2, 4, 8, 16 beams)
- **Y-axis**: "Accuracy (%)" (linear scale: 55% to 72.5% in 2.5% increments)
- **Legend**: Located at the bottom-right, with five entries:
- Orange dashed line: ThinkPRM-1.5B
- Green solid line: DiscPRM-1.5B
- Orange dotted line: ThinkPRM-1.5B@4
- Brown solid line: MathShepherd-7B
- Purple solid line: RLHFFlow-8B-Deepseek
### Detailed Analysis
1. **ThinkPRM-1.5B (orange dashed)**:
- Starts at 62.5% accuracy at 2⁰ beams.
- Increases steadily to 67.5% at 2⁴ beams.
- Slope: ~0.5% per beam doubling.
2. **DiscPRM-1.5B (green solid)**:
- Starts at 57.5% accuracy at 2⁰ beams.
- Rises to 65% at 2⁴ beams.
- Slope: ~1.25% per beam doubling.
3. **ThinkPRM-1.5B@4 (orange dotted)**:
- Starts at 65% accuracy at 2⁰ beams.
- Peaks at 67.5% at 2⁴ beams.
- Slope: ~0.3% per beam doubling.
4. **MathShepherd-7B (brown solid)**:
- Starts at 55% accuracy at 2⁰ beams.
- Ends at 62.5% at 2⁴ beams.
- Slope: ~1.875% per beam doubling.
5. **RLHFFlow-8B-Deepseek (purple solid)**:
- Starts at 55% accuracy at 2⁰ beams.
- Ends at 65% at 2⁴ beams.
- Slope: ~1.25% per beam doubling.
### Key Observations
- **Highest accuracy**: ThinkPRM-1.5B@4 (orange dotted) achieves 67.5% at 2⁴ beams.
- **Steepest improvement**: RLHFFlow-8B-Deepseek (purple) shows the largest absolute gain (+10% from 2⁰ to 2⁴).
- **Lowest baseline**: MathShepherd-7B (brown) starts at 55% but improves consistently.
- **Divergence**: ThinkPRM-1.5B (dashed) and ThinkPRM-1.5B@4 (dotted) converge at 67.5% at 2⁴ beams.
### Interpretation
The chart demonstrates that increasing the number of beams generally improves accuracy across all models, with diminishing returns after 2³ beams. The ThinkPRM-1.5B@4 variant (orange dotted) outperforms others at higher beam counts, suggesting it is optimized for this task. The RLHFFlow-8B-Deepseek model (purple) shows the most significant improvement with beam expansion, indicating potential for further optimization. MathShepherd-7B (brown) underperforms relative to others, possibly due to architectural limitations or training data differences. The convergence of ThinkPRM variants at 2⁴ beams highlights the importance of beam count in balancing exploration and computational cost.