## Flow Diagram: Language Processing Pipeline
### Overview
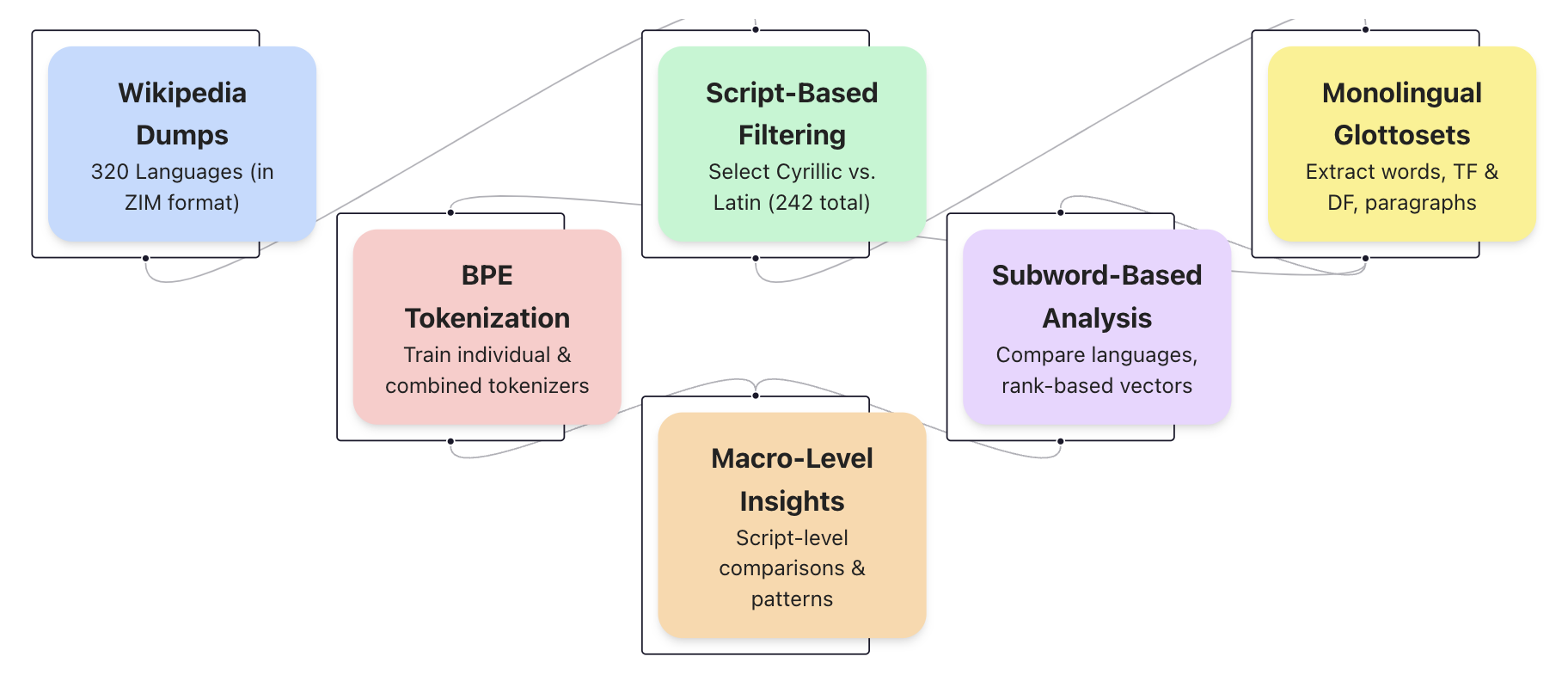
The image is a flow diagram illustrating a language processing pipeline. It outlines the steps involved in processing Wikipedia dumps for linguistic analysis, starting from data acquisition and preprocessing to analysis and insights. The diagram uses rounded rectangles to represent different stages, connected by lines to indicate the flow of data.
### Components/Axes
The diagram consists of the following components:
1. **Wikipedia Dumps:** (Light Blue)
* Description: "320 Languages (in ZIM format)"
2. **BPE Tokenization:** (Light Red)
* Description: "Train individual & combined tokenizers"
3. **Script-Based Filtering:** (Light Green)
* Description: "Select Cyrillic vs. Latin (242 total)"
4. **Macro-Level Insights:** (Light Orange)
* Description: "Script-level comparisons & patterns"
5. **Subword-Based Analysis:** (Light Purple)
* Description: "Compare languages, rank-based vectors"
6. **Monolingual Glottosets:** (Light Yellow)
* Description: "Extract words, TF & DF, paragraphs"
The flow of data is indicated by lines connecting these components.
### Detailed Analysis or ### Content Details
* **Wikipedia Dumps** (Light Blue) is the starting point, feeding into both **BPE Tokenization** (Light Red) and **Script-Based Filtering** (Light Green).
* **BPE Tokenization** (Light Red) feeds into **Macro-Level Insights** (Light Orange).
* **Script-Based Filtering** (Light Green) feeds into both **Subword-Based Analysis** (Light Purple) and **Monolingual Glottosets** (Light Yellow).
* **Macro-Level Insights** (Light Orange) feeds into **Subword-Based Analysis** (Light Purple).
* **Subword-Based Analysis** (Light Purple) feeds into **Monolingual Glottosets** (Light Yellow).
### Key Observations
* The pipeline starts with raw Wikipedia data and progresses through tokenization, filtering, and analysis stages.
* There are two parallel paths from the initial data: one focusing on tokenization and macro-level insights, and the other on script-based filtering and subword analysis.
* The final stage involves creating monolingual glottosets, suggesting the goal is to extract and organize language-specific data.
### Interpretation
The diagram illustrates a comprehensive approach to processing multilingual Wikipedia data for linguistic research. The pipeline combines different techniques, including tokenization, script-based filtering, and subword analysis, to extract meaningful insights and create language-specific datasets. The parallel paths suggest different analytical approaches that converge in the final stage of glottoset creation. The diagram highlights the complexity of multilingual data processing and the need for a multi-faceted approach to extract valuable information.