\n
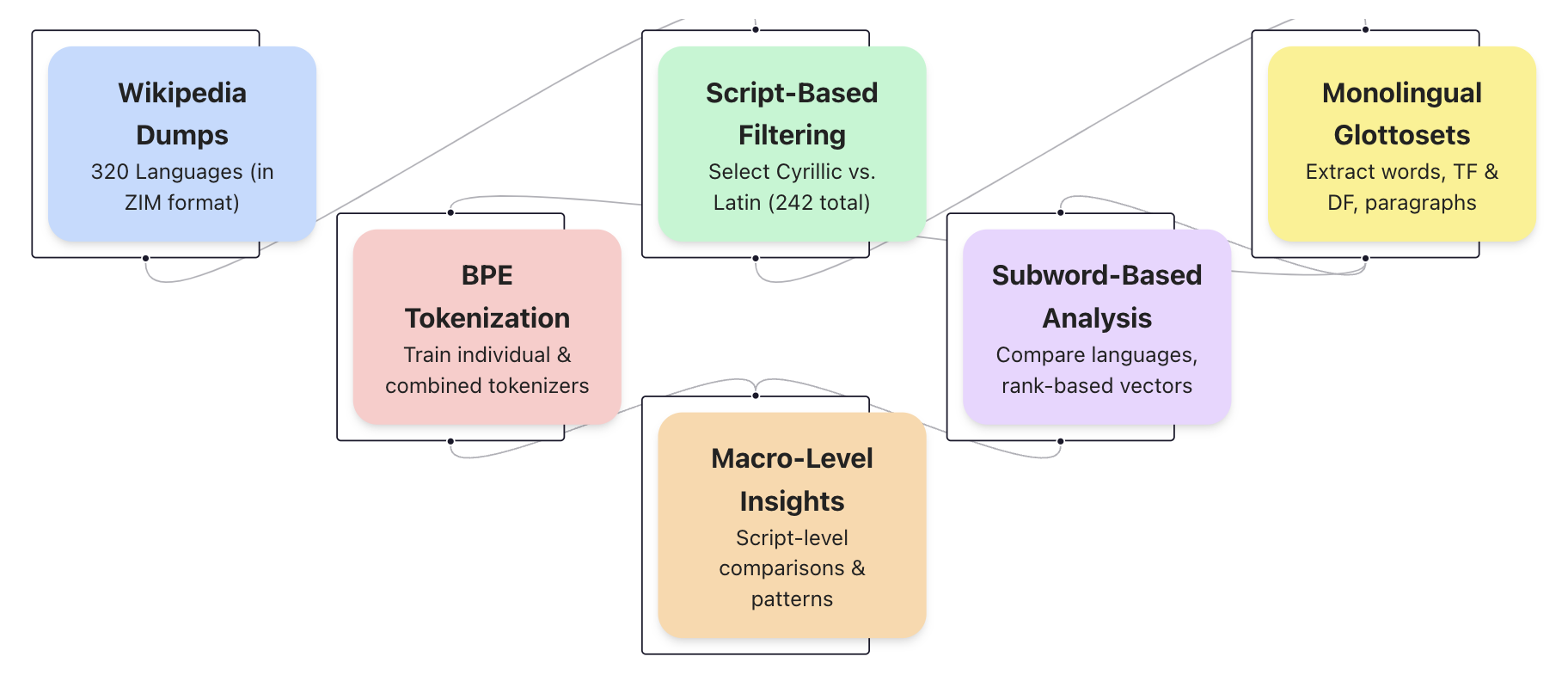
## Diagram: Data Processing Pipeline for Multilingual Wikipedia Analysis
### Overview
This diagram illustrates a data processing pipeline used for analyzing multilingual Wikipedia data. The pipeline begins with Wikipedia dumps, filters based on script, performs tokenization, conducts subword-based analysis, and ultimately derives macro-level insights. The diagram uses colored boxes connected by arrows to represent the flow of data and processing steps.
### Components/Axes
The diagram consists of seven rectangular components, each representing a stage in the pipeline. These are:
1. **Wikipedia Dumps:** (Light Blue) - "320 Languages (in ZIM format)"
2. **Script-Based Filtering:** (Light Green) - "Select Cyrillic vs. Latin (242 total)"
3. **Monolingual Glottosets:** (Light Purple) - "Extract words, TF & DF, paragraphs"
4. **BPE Tokenization:** (Salmon/Orange) - "Train individual & combined tokenizers"
5. **Subword-Based Analysis:** (Dark Purple) - "Compare languages, rank-based vectors"
6. **Macro-Level Insights:** (Brown) - "Script-level comparisons & patterns"
Arrows indicate the direction of data flow between these components.
### Detailed Analysis or Content Details
The pipeline proceeds as follows:
1. **Wikipedia Dumps** (top-left) provides the initial data source, containing data from 320 languages in ZIM format.
2. This data is fed into **Script-Based Filtering** (top-center), which selects data based on script, specifically focusing on Cyrillic versus Latin scripts, resulting in a total of 242 languages.
3. The filtered data is then split into two parallel paths:
* One path leads to **Monolingual Glottosets** (top-right), where words, Term Frequency (TF), Document Frequency (DF), and paragraphs are extracted.
* The other path goes to **BPE Tokenization** (center-left), where individual and combined tokenizers are trained.
4. The output of both **Script-Based Filtering** and **BPE Tokenization** converge into **Subword-Based Analysis** (bottom-center), which compares languages using rank-based vectors.
5. Finally, **Subword-Based Analysis** feeds into **Macro-Level Insights** (bottom-center), which focuses on script-level comparisons and pattern identification.
### Key Observations
The diagram highlights a parallel processing approach, with monolingual analysis occurring alongside tokenization-based analysis. The focus on script-based filtering suggests an interest in comparing languages with different writing systems. The inclusion of TF and DF in the monolingual glottosets indicates a focus on statistical analysis of word usage.
### Interpretation
This diagram represents a sophisticated approach to analyzing multilingual text data. The pipeline is designed to extract meaningful insights from Wikipedia content by first filtering based on script, then processing the data through both monolingual and subword-based analysis techniques. The ultimate goal is to identify patterns and comparisons at the script level, potentially revealing linguistic or cultural differences between languages. The use of BPE tokenization suggests an attempt to handle the challenges of morphological variation across languages. The parallel processing structure allows for a comprehensive analysis that combines statistical and linguistic approaches. The diagram does not contain any numerical data, but rather outlines a methodological process.