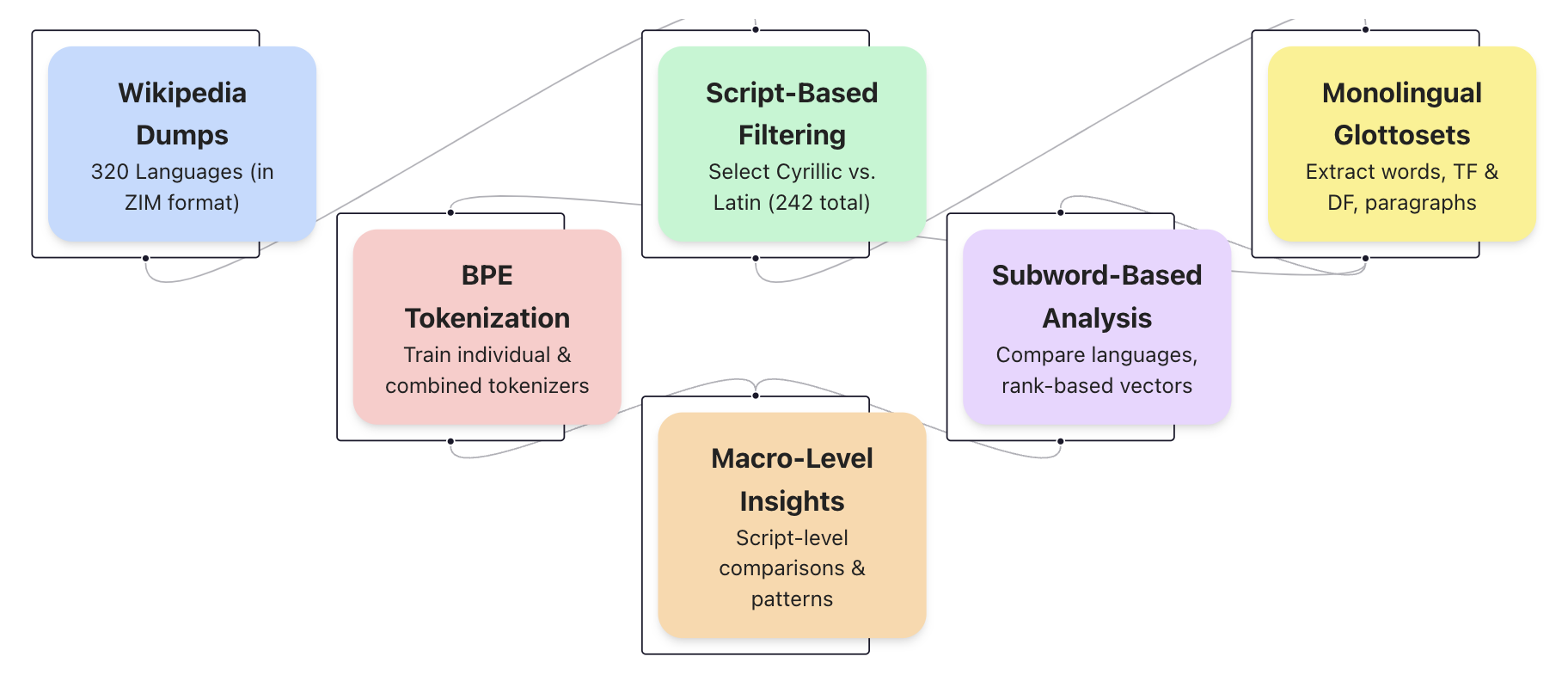
## Flowchart: Multilingual Language Processing Pipeline
### Overview
The diagram illustrates a multistage pipeline for processing linguistic data across 320 languages, starting with raw Wikipedia dumps and culminating in monolingual glottosets. The flowchart uses color-coded nodes connected by bidirectional arrows to represent data flow and interdependencies between processing stages.
### Components/Axes
1. **Nodes** (color-coded):
- **Wikipedia Dumps** (blue): 320 languages in ZIM format
- **BPE Tokenization** (pink): Training individual & combined tokenizers
- **Script-Based Filtering** (green): Selecting Cyrillic vs. Latin scripts (242 total)
- **Monolingual Glottosets** (yellow): Extracting words, TF/DF, paragraphs
- **Subword-Based Analysis** (purple): Language comparisons using rank-based vectors
- **Macro-Level Insights** (orange): Script-level comparisons & patterns
2. **Connections**:
- Bidirectional arrows indicate data flow between stages
- Primary flow direction: Left-to-right (top-left to bottom-right)
- Feedback loops between tokenization and analysis stages
### Detailed Analysis
1. **Data Flow**:
- **Wikipedia Dumps** → **BPE Tokenization** (direct input)
- **Wikipedia Dumps** → **Script-Based Filtering** (parallel processing)
- **BPE Tokenization** → **Macro-Level Insights** (script comparisons)
- **BPE Tokenization** → **Subword-Based Analysis** (language comparisons)
- **Script-Based Filtering** → **Monolingual Glottosets** (filtered output)
- **Subword-Based Analysis** → **Monolingual Glottosets** (vector-based inputs)
2. **Key Data Points**:
- 320 languages processed from initial dumps
- 242 languages survive script filtering (Cyrillic vs. Latin)
- Dual-path processing: Tokenization and script filtering both feed into glottoset creation
- Subword analysis provides comparative vectors for language relationships
### Key Observations
1. **Bidirectional Flow**: Arrows between BPE Tokenization and Subword Analysis suggest iterative refinement
2. **Script Filtering Bottleneck**: 242 languages (75.6% of original) survive filtering, indicating significant script-based reduction
3. **Convergent Output**: All paths ultimately feed into Monolingual Glottosets, emphasizing its role as final processing stage
4. **Color Coding**: Distinct colors for each node type enhance visual separation of processing stages
### Interpretation
This pipeline demonstrates a hierarchical approach to multilingual NLP processing:
1. **Data Preparation**: Raw Wikipedia dumps (320 languages) require preprocessing through BPE tokenization and script filtering
2. **Parallel Processing**: Tokenization and script filtering operate concurrently but feed into different analysis paths
3. **Comparative Analysis**: Subword-based methods enable language comparisons through rank-based vectors
4. **Script-Level Insights**: Macro-level analysis focuses on script-specific patterns, suggesting potential for cross-linguistic pattern discovery
5. **Final Output**: Monolingual glottosets represent the distilled output containing extracted linguistic features (words, TF/DF statistics, paragraphs)
The bidirectional arrows between tokenization and analysis stages imply an iterative refinement process, where analysis results may inform tokenizer improvements. The script filtering stage acts as a critical quality control checkpoint, reducing the dataset size while maintaining linguistic diversity through Cyrillic/Latin selection.