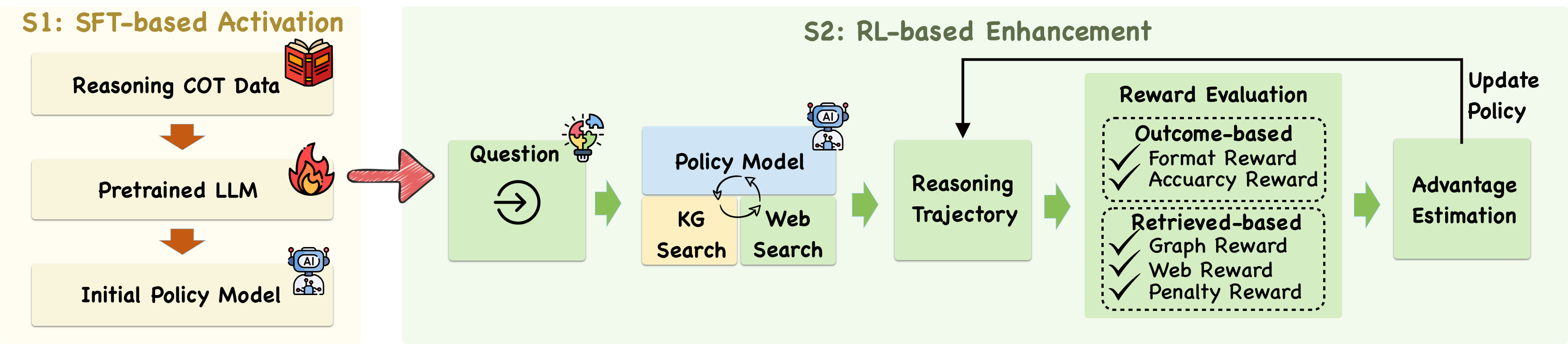
## Diagram: SFT-based Activation and RL-based Enhancement
### Overview
The image is a diagram illustrating a two-stage process: SFT-based Activation (S1) and RL-based Enhancement (S2). It outlines the steps involved in training a policy model using supervised fine-tuning (SFT) and reinforcement learning (RL).
### Components/Axes
**S1: SFT-based Activation (Left Side)**
* **Reasoning COT Data:** Top box, contains an icon of a book.
* **Pretrained LLM:** Middle box, contains an icon of a flame.
* **Initial Policy Model:** Bottom box, contains an icon of a robot with "AI" on its chest.
* Arrows indicate the flow from Reasoning COT Data to Pretrained LLM, and from Pretrained LLM to Initial Policy Model.
**S2: RL-based Enhancement (Right Side)**
* **Question:** First green box, contains an icon of a target.
* **Policy Model:** Blue box, contains an icon of a robot with "AI" on its chest.
* **KG Search:** Yellow box.
* **Web Search:** Yellow box.
* A circular arrow connects Policy Model with KG Search and Web Search.
* **Reasoning Trajectory:** Green box.
* **Reward Evaluation:** Green box, divided into two sections:
* **Outcome-based:**
* Format Reward (with a checkmark)
* Accuracy Reward (with a checkmark)
* **Retrieved-based:**
* Graph Reward (with a checkmark)
* Web Reward (with a checkmark)
* Penalty Reward (with a checkmark)
* **Advantage Estimation:** Green box.
* **Update Policy:** Green box.
* Arrows indicate the flow from Question to Policy Model, from Policy Model to Reasoning Trajectory, from Reasoning Trajectory to Reward Evaluation, from Reward Evaluation to Advantage Estimation, and from Advantage Estimation to Update Policy. A feedback loop connects Update Policy back to Policy Model.
### Detailed Analysis or Content Details
**S1: SFT-based Activation**
1. The process begins with "Reasoning COT Data," suggesting the use of chain-of-thought (COT) data for training.
2. This data is fed into a "Pretrained LLM" (Large Language Model).
3. The output is an "Initial Policy Model."
**S2: RL-based Enhancement**
1. A "Question" is posed to the system.
2. The "Policy Model" interacts with "KG Search" (Knowledge Graph Search) and "Web Search" in a loop.
3. The result is a "Reasoning Trajectory."
4. "Reward Evaluation" assesses the trajectory based on "Outcome-based" and "Retrieved-based" rewards.
* "Outcome-based" rewards include "Format Reward" and "Accuracy Reward."
* "Retrieved-based" rewards include "Graph Reward," "Web Reward," and "Penalty Reward."
5. "Advantage Estimation" is performed.
6. The "Policy" is updated based on the advantage estimation.
### Key Observations
* The diagram illustrates a two-stage training process for a policy model.
* SFT-based Activation initializes the model using supervised learning.
* RL-based Enhancement refines the model using reinforcement learning with rewards based on both outcome and retrieved information.
* The use of KG Search and Web Search suggests the model is designed to leverage external knowledge sources.
### Interpretation
The diagram presents a method for training a policy model that combines the strengths of supervised fine-tuning and reinforcement learning. The SFT-based Activation provides a strong initial model, while the RL-based Enhancement allows the model to learn from its interactions with the environment and improve its reasoning abilities. The inclusion of KG Search and Web Search indicates an effort to ground the model's reasoning in external knowledge, potentially improving its accuracy and robustness. The reward structure, which includes both outcome-based and retrieved-based rewards, encourages the model to not only produce accurate answers but also to effectively utilize external knowledge sources.