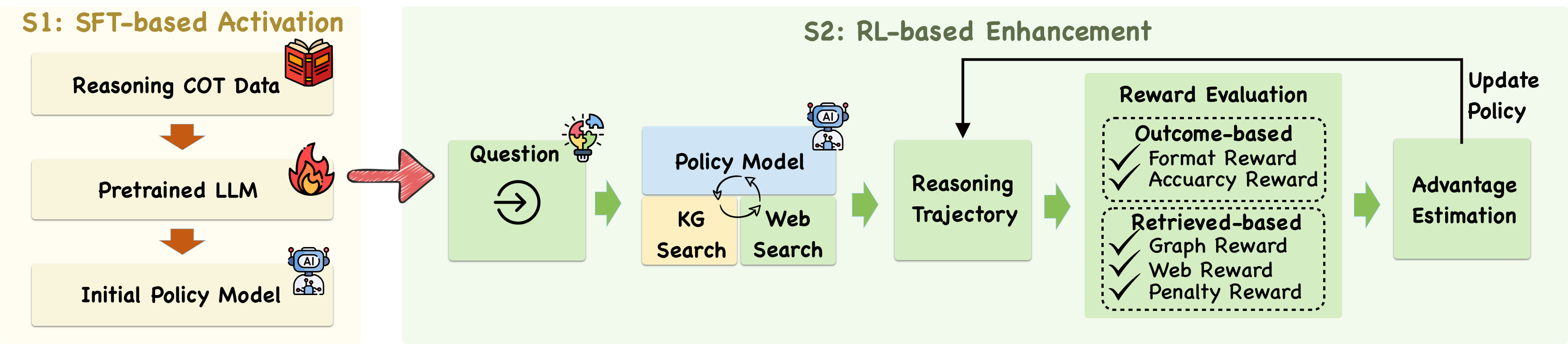
## Diagram: Two-Stage AI Model Training Pipeline
### Overview
The image is a technical flowchart illustrating a two-stage process for training an AI model, specifically a Large Language Model (LLM). The process is divided into "S1: SFT-based Activation" and "S2: RL-based Enhancement," showing how an initial model is created and then refined using reinforcement learning with external knowledge retrieval.
### Components/Axes
The diagram is structured as a horizontal flowchart moving from left to right, divided into two main colored regions:
* **Left Region (Beige Background):** Labeled **"S1: SFT-based Activation"**.
* **Right Region (Light Green Background):** Labeled **"S2: RL-based Enhancement"**.
**Key Components and Flow:**
1. **S1: SFT-based Activation (Left Region):**
* **Component 1:** A beige box labeled **"Reasoning COT Data"** with a red book icon. An orange arrow points down to the next component.
* **Component 2:** A beige box labeled **"Pretrained LLM"** with a fire icon. An orange arrow points down to the next component.
* **Component 3:** A beige box labeled **"Initial Policy Model"** with a blue robot/AI icon.
* **Flow:** A large, red, right-pointing arrow connects the output of the "Initial Policy Model" to the start of the S2 stage.
2. **S2: RL-based Enhancement (Right Region):**
* **Input:** A light green box labeled **"Question"** with a lightbulb/puzzle piece icon and a circular arrow icon inside.
* **Process Block:** A blue box labeled **"Policy Model"** with a robot icon. Below it are two connected beige boxes: **"KG Search"** (Knowledge Graph Search) and **"Web Search"**. Circular arrows indicate an iterative or interactive process between the Policy Model and these search functions.
* **Output of Process:** A light green box labeled **"Reasoning Trajectory"**.
* **Evaluation Block:** A large light green box labeled **"Reward Evaluation"**. This contains two dotted-line sub-boxes:
* **Top Sub-box:** Labeled **"Outcome-based"**. It lists two reward types with checkmarks: **"Format Reward"** and **"Accuracy Reward"** (note: "Accuracy" is misspelled as "Accuarcy" in the image).
* **Bottom Sub-box:** Labeled **"Retrieved-based"**. It lists three reward types with checkmarks: **"Graph Reward"**, **"Web Reward"**, and **"Penalty Reward"**.
* **Estimation:** A light green box labeled **"Advantage Estimation"**.
* **Feedback Loop:** A black arrow originates from the "Advantage Estimation" box, goes up and left, and points back to the "Reasoning Trajectory" box. The text **"Update Policy"** is written next to the vertical segment of this arrow, indicating the policy model is updated based on the estimated advantage.
### Detailed Analysis
The diagram details a sequential and cyclical training pipeline:
**Stage 1 (SFT-based Activation):**
* **Purpose:** To create an initial policy model capable of reasoning.
* **Process:** Supervised Fine-Tuning (SFT) is performed. "Reasoning COT (Chain-of-Thought) Data" is used to fine-tune a "Pretrained LLM," resulting in an "Initial Policy Model."
**Stage 2 (RL-based Enhancement):**
* **Purpose:** To enhance the initial policy model's performance through reinforcement learning (RL) and external knowledge.
* **Process Flow:**
1. A **"Question"** is input.
2. The **"Policy Model"** interacts with **"KG Search"** and **"Web Search"** modules to gather information.
3. This generates a **"Reasoning Trajectory"** (the model's step-by-step reasoning process).
4. The trajectory is evaluated by the **"Reward Evaluation"** module, which calculates rewards based on two criteria:
* **Outcome-based:** Assesses the final answer's format and accuracy.
* **Retrieved-based:** Assesses the quality and relevance of information retrieved from the knowledge graph and web, and applies penalties (likely for hallucinations or poor retrieval).
5. The rewards are used for **"Advantage Estimation"** (a key step in RL algorithms like PPO to determine how much better an action was than expected).
6. The estimated advantage is used to **"Update Policy"**, creating a feedback loop that improves the Policy Model for future questions.
### Key Observations
1. **Two-Stage Architecture:** The process clearly separates initial capability activation (SFT) from subsequent performance enhancement (RL).
2. **Hybrid Retrieval:** The Policy Model is augmented with both structured (Knowledge Graph) and unstructured (Web) search capabilities.
3. **Multi-faceted Reward System:** The reward function is composite, evaluating not just the final outcome but also the quality of the intermediate retrieval and reasoning process. The inclusion of a "Penalty Reward" suggests a mechanism to discourage undesirable behaviors.
4. **Closed-Loop RL:** The "Update Policy" feedback loop confirms this is an iterative online or offline reinforcement learning process where the model improves from its own generated trajectories.
### Interpretation
This diagram outlines a sophisticated methodology for training a reasoning-capable LLM that can leverage external knowledge. The **SFT stage** "activates" the model's latent reasoning abilities by training it on curated chain-of-thought data. The **RL stage** then "enhances" this foundation by allowing the model to learn from trial and error in a more dynamic environment.
The core innovation lies in the **Reward Evaluation** design. By decomposing rewards into outcome-based and retrieved-based components, the training signal encourages the model to not only arrive at correct answers but also to do so by finding high-quality, relevant information from external sources. This addresses a key weakness of standard LLMs—their static knowledge and tendency to hallucinate. The "Penalty Reward" likely acts as a safeguard against generating incorrect or unsupported information during retrieval.
The entire pipeline represents a move from static model fine-tuning towards creating an **agent** that can actively seek information, reason over it, and be rewarded for robust, verifiable processes. This approach is crucial for developing reliable AI systems for complex question-answering, research, and decision-support tasks where accuracy and traceability of information are paramount.