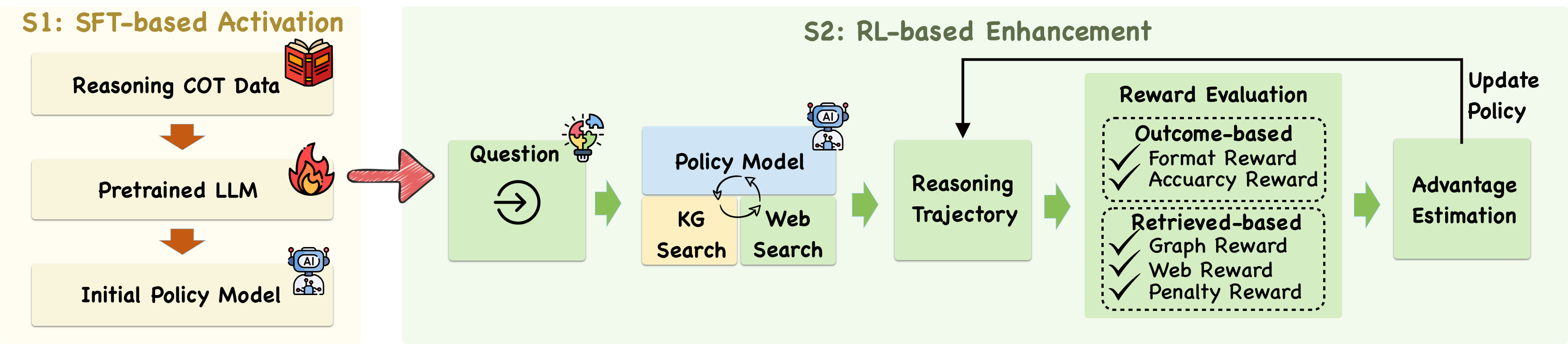
## Flowchart: Hybrid AI System Architecture for Reasoning and Policy Optimization
### Overview
The diagram illustrates a two-stage hybrid AI system combining Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) for reasoning and policy optimization. The system progresses from initial data processing to dynamic policy updates through iterative feedback loops.
### Components/Axes
**S1: SFT-based Activation (Left Section)**
1. **Reasoning COT Data** (Book icon)
- Input data source for initial training
2. **Pretrained LLM** (Flame icon)
- Core language model processing unit
3. **Initial Policy Model** (Robot icon)
- First iteration of policy generation
**S2: RL-based Enhancement (Right Section)**
1. **Question** (Lightbulb icon)
- Starting point for reasoning cycle
2. **Policy Model** (Central blue box)
- Core decision-making component
3. **Knowledge Graph (KG) Search** (Yellow box)
- Structured data retrieval
4. **Web Search** (Green box)
- Unstructured web data retrieval
5. **Reasoning Trajectory** (Green box)
- Intermediate processing stage
6. **Reward Evaluation** (Dotted box)
- Contains two reward types:
- **Outcome-based Reward**
- Format Reward ✓
- Accuracy Reward ✓
- **Retrieved-based Reward**
- Graph Reward ✓
- Web Reward ✓
- Penalty Reward ✓
7. **Advantage Estimation** (Green box)
- Performance evaluation metric
8. **Update Policy** (Final green box)
- Feedback loop to Policy Model
### Flow Direction
- S1 flows linearly: COT Data → Pretrained LLM → Initial Policy Model
- S2 forms a cyclical process:
Question → Policy Model → (KG/Web Search) → Reasoning Trajectory → Reward Evaluation → Advantage Estimation → Update Policy → (loop back to Policy Model)
### Key Observations
1. **Hybrid Architecture**: Combines SFT initialization with RL refinement
2. **Multi-source Data Integration**: Uses both structured (KG) and unstructured (Web) data
3. **Multi-criteria Reward System**: Evaluates performance through format, accuracy, graph, web, and penalty metrics
4. **Closed-loop System**: Policy updates create continuous improvement cycle
5. **Visual Hierarchy**: S1 uses warmer colors (red/orange), S2 uses cooler colors (green/blue)
### Interpretation
This architecture demonstrates a sophisticated approach to AI reasoning system development:
1. **Initial Training Phase (S1)**: Establishes foundational reasoning capabilities through supervised learning on chain-of-thought data
2. **Dynamic Enhancement Phase (S2)**: Implements RL to:
- Continuously adapt to new questions
- Leverage both structured and unstructured data sources
- Optimize policies through multi-faceted reward evaluation
- Maintain performance through iterative policy updates
The system's strength lies in its ability to combine the stability of SFT initialization with the adaptability of RL, creating a robust framework for handling complex reasoning tasks while maintaining up-to-date knowledge through continuous learning. The explicit separation of outcome-based and retrieved-based rewards suggests a deliberate design choice to balance internal model performance with external data relevance.