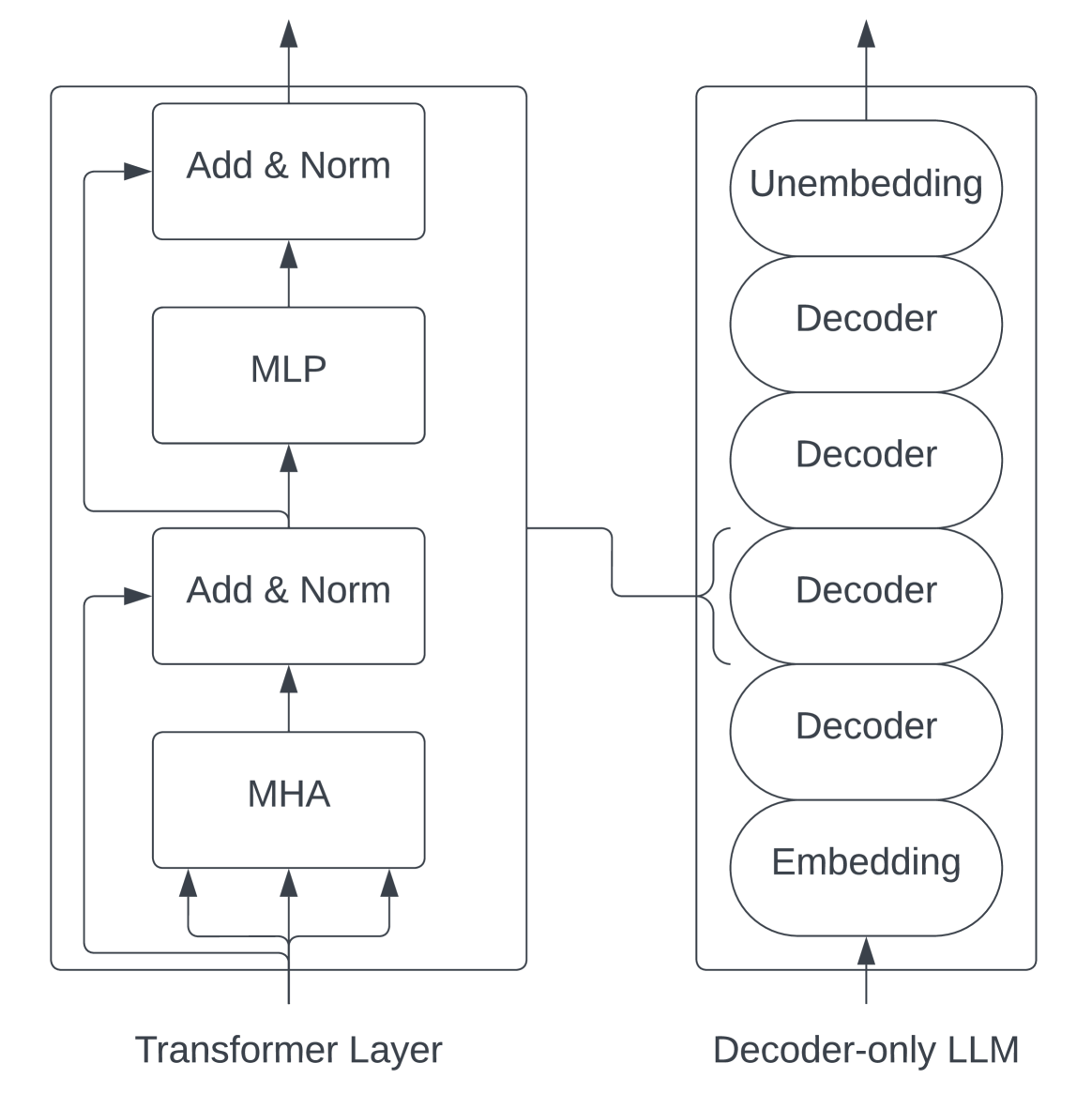
# Technical Diagram Analysis: Transformer Layer vs Decoder-only LLM
## Diagram Overview
The image compares two neural network architectures through labeled components and directional flow arrows. Two primary blocks are depicted:
1. **Transformer Layer** (left)
2. **Decoder-only LLM** (right)
---
## Transformer Layer Components
### Spatial Layout
- **Vertical Stack** of four processing blocks
- **Bidirectional Connections** between components
### Component Breakdown
1. **Multi-Head Attention (MHA)**
- Position: Bottom-most block
- Connections:
- 3 upward arrows to **Add & Norm** (left)
- 1 rightward arrow to **Add & Norm** (center)
2. **MLP (Multi-Layer Perceptron)**
- Position: Middle block
- Connections:
- 1 upward arrow from **Add & Norm** (center)
- 1 downward arrow to **Add & Norm** (left)
3. **Add & Norm Blocks**
- **Left Block**:
- Receives input from MHA (3 arrows)
- Outputs to MHA (1 arrow)
- **Center Block**:
- Receives input from MLP (1 arrow)
- Outputs to MLP (1 arrow)
- **Right Block**:
- Receives input from MHA (1 arrow)
- Outputs to MHA (1 arrow)
4. **Residual Connections**
- All Add & Norm blocks implement residual connections
- Normalization layers follow addition operations
---
## Decoder-only LLM Architecture
### Component Stack
1. **Embedding Layer**
- Position: Bottom-most
- Function: Input token conversion
2. **Decoder Stack**
- **Four Identical Decoder Blocks** (stacked vertically)
- Each block contains:
- Self-attention mechanism
- Cross-attention mechanism
- Feed-forward network
- Residual connections
3. **Unembedding Layer**
- Position: Top-most
- Function: Output token reconstruction
### Data Flow
- **Bottom-to-Top** processing sequence
- Embedding → Decoder 1 → Decoder 2 → Decoder 3 → Decoder 4 → Unembedding
---
## Key Architectural Differences
| Feature | Transformer Layer | Decoder-only LLM |
|------------------------|----------------------------------|---------------------------------|
| **Directionality** | Bidirectional flow | Unidirectional flow |
| **Component Repetition**| 2 Add & Norm blocks | 4 Decoder blocks |
| **Attention Type** | Multi-head attention | Self/cross-attention |
| **Normalization** | Explicit Add & Norm blocks | Implicit in decoder blocks |
---
## Technical Notes
1. **Transformer Layer**:
- Follows standard transformer block architecture
- Contains pre-layer normalization (Add & Norm before MHA/MLP)
2. **Decoder-only LLM**:
- Resembles GPT-style architecture
- Lacks encoder components present in full transformers
- Uses tied embeddings (embedding/unembedding weight sharing)
3. **Arrow Conventions**:
- Black arrows: Data flow direction
- Dashed lines: Residual connections
- Solid lines: Primary data paths
---
## Missing Elements
- No numerical data or performance metrics
- No explicit parameter counts
- No activation function specifications
- No positional encoding details
This diagram focuses on architectural comparison rather than quantitative analysis.