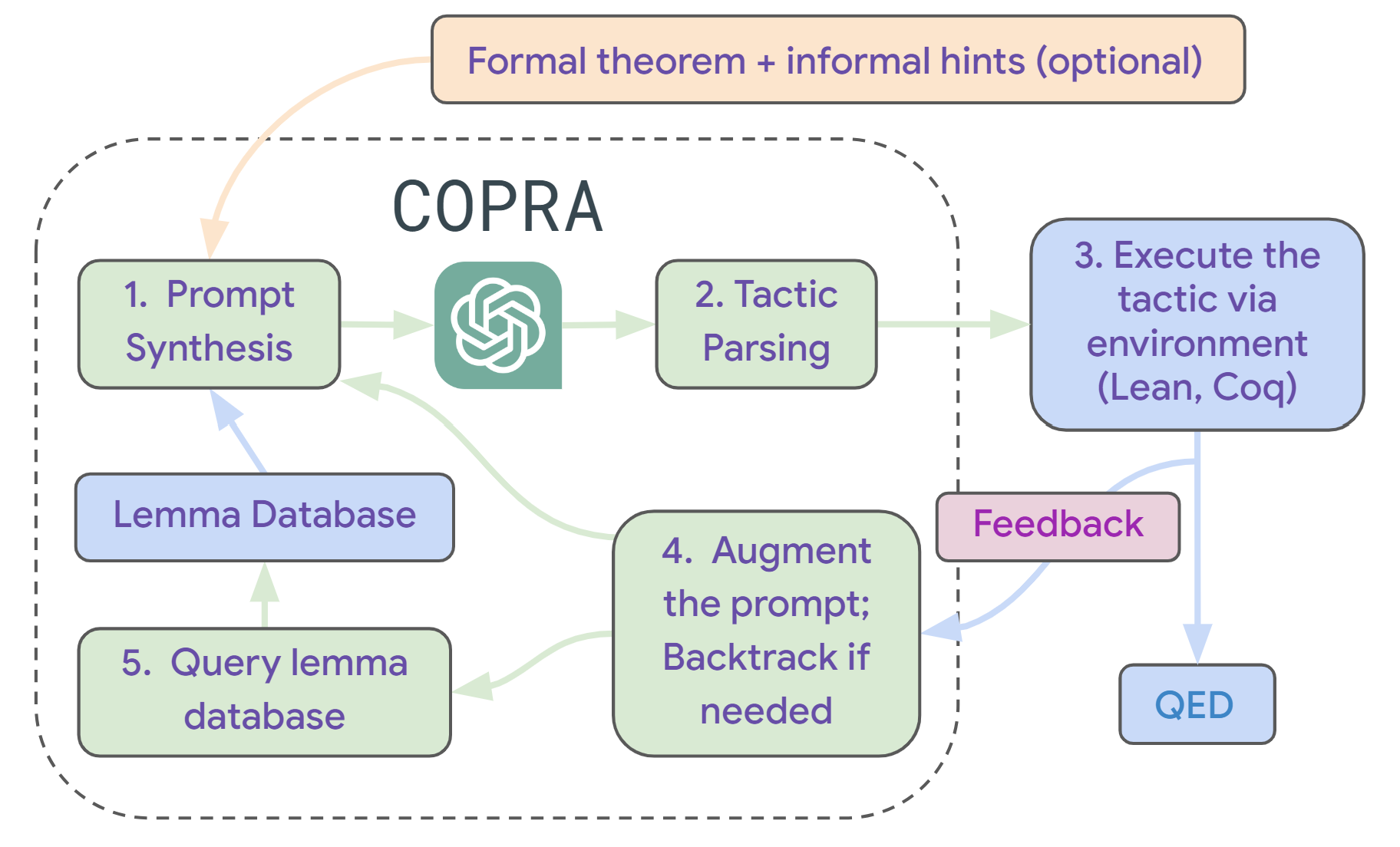
## Diagram: COPRA Workflow
### Overview
The image is a flowchart illustrating the COPRA workflow. It outlines the steps involved in a system that uses prompt synthesis, tactic parsing, and lemma databases to achieve a goal, potentially related to theorem proving or code generation. The flow includes feedback loops and backtracking mechanisms.
### Components/Axes
* **Title:** COPRA (centered at the top)
* **Nodes:**
* Formal theorem + informal hints (optional) (top, orange box)
* 1. Prompt Synthesis (top-left, green box)
* 2. Tactic Parsing (top-center, green box)
* 3. Execute the tactic via environment (Lean, Coq) (top-right, blue box)
* Lemma Database (middle-left, blue box)
* 4. Augment the prompt; Backtrack if needed (center-right, green box)
* 5. Query lemma database (bottom-left, green box)
* Feedback (right, pink box)
* QED (bottom-right, blue box)
* **Arrows:** Indicate the flow of information and control between the nodes.
* **Logo:** A stylized logo, possibly representing a generative model, is positioned between "1. Prompt Synthesis" and "2. Tactic Parsing".
### Detailed Analysis
The workflow begins with "Formal theorem + informal hints (optional)". This input feeds into "1. Prompt Synthesis". The output of "1. Prompt Synthesis" goes to both the logo and "2. Tactic Parsing". The output of "2. Tactic Parsing" goes to "3. Execute the tactic via environment (Lean, Coq)". The output of "3. Execute the tactic via environment (Lean, Coq)" goes to "Feedback" and then to "QED". "Feedback" also goes to "4. Augment the prompt; Backtrack if needed". "4. Augment the prompt; Backtrack if needed" goes to "1. Prompt Synthesis". "1. Prompt Synthesis" also goes to "Lemma Database". "Lemma Database" goes to "5. Query lemma database". "5. Query lemma database" goes to "4. Augment the prompt; Backtrack if needed".
* **Formal theorem + informal hints (optional):** This is the starting point, suggesting an initial problem or goal.
* **1. Prompt Synthesis:** This step likely involves generating a structured prompt or query based on the initial input.
* **2. Tactic Parsing:** The prompt is parsed into a series of tactics or actions.
* **3. Execute the tactic via environment (Lean, Coq):** The tactics are executed within a specific environment, possibly a theorem prover like Lean or Coq.
* **Lemma Database:** A database of previously proven lemmas or code snippets.
* **4. Augment the prompt; Backtrack if needed:** The prompt is refined based on feedback, and the system can backtrack if necessary.
* **5. Query lemma database:** The system queries the lemma database for relevant information.
* **Feedback:** The result of executing the tactics is evaluated, providing feedback for prompt augmentation.
* **QED:** Indicates the successful completion of the process (Quod Erat Demonstrandum).
### Key Observations
* The workflow is iterative, with a feedback loop between "Feedback" and "4. Augment the prompt; Backtrack if needed", allowing the system to refine its approach.
* The "Lemma Database" and "5. Query lemma database" suggest the system leverages existing knowledge to solve problems.
* The inclusion of "Lean, Coq" indicates a focus on formal verification or theorem proving.
### Interpretation
The COPRA workflow appears to be a system designed for automated problem-solving, likely in the domain of formal verification or code generation. It uses a combination of prompt synthesis, tactic parsing, and lemma databases to achieve its goals. The feedback loop and backtracking mechanism allow the system to adapt and improve its performance over time. The use of "Lean, Coq" suggests a focus on rigorous, provably correct solutions. The system takes an initial problem, generates a series of tactics, executes them in a formal environment, and then refines its approach based on feedback. The "QED" indicates a successful proof or solution has been found.