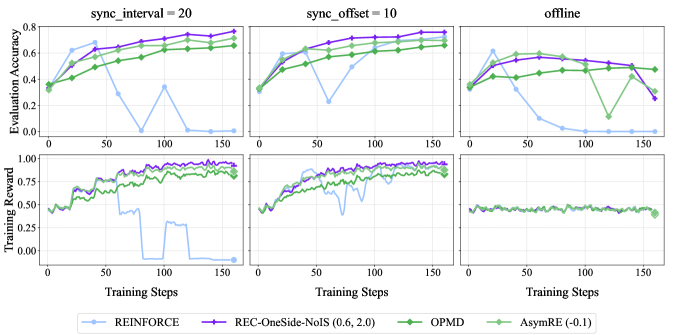
## Chart: Training Performance Comparison
### Overview
The image presents a 2x3 grid of line charts comparing the training performance of four reinforcement learning algorithms – REINFORCE, REC-OneSide-NoIS (0.6, 2.0), OPMD, and AsymRE (-0.1) – under three different synchronization conditions: `sync_interval = 20`, `sync_offset = 10`, and `offline`. Each synchronization condition is represented by a column, and each row displays a different metric: Evaluation Accuracy (top row) and Training Reward (bottom row). The x-axis for all charts represents "Training Steps", ranging from 0 to 150.
### Components/Axes
* **X-axis:** Training Steps (0 to 150)
* **Y-axis (Top Charts):** Evaluation Accuracy (0 to 0.8)
* **Y-axis (Bottom Charts):** Training Reward (0 to 1.0)
* **Columns:**
* `sync_interval = 20`
* `sync_offset = 10`
* `offline`
* **Legend:**
* REINFORCE (Light Blue)
* REC-OneSide-NoIS (0.6, 2.0) (Blue)
* OPMD (Green)
* AsymRE (-0.1) (Magenta)
### Detailed Analysis or Content Details
**Column 1: `sync_interval = 20`**
* **Evaluation Accuracy:**
* REINFORCE: Starts at approximately 0.1, increases to around 0.75 by step 50, fluctuates between 0.7 and 0.8 for the remainder of the training.
* REC-OneSide-NoIS (0.6, 2.0): Starts at approximately 0.1, increases to around 0.7 by step 50, and remains relatively stable around 0.7-0.8.
* OPMD: Starts at approximately 0.2, increases steadily to around 0.75 by step 150.
* AsymRE (-0.1): Starts at approximately 0.2, increases to around 0.6 by step 50, then decreases to around 0.4 by step 100, and recovers slightly to around 0.5 by step 150.
* **Training Reward:**
* REINFORCE: Exhibits significant fluctuations, starting around 0.3, dropping to near 0 at step 25, and then oscillating between 0.2 and 0.6.
* REC-OneSide-NoIS (0.6, 2.0): Starts around 0.3, drops to near 0 at step 25, and then oscillates between 0.2 and 0.6.
* OPMD: Remains relatively stable around 0.7-0.8 throughout the training process.
* AsymRE (-0.1): Starts around 0.4, drops to near 0 at step 25, and then oscillates between 0.2 and 0.6.
**Column 2: `sync_offset = 10`**
* **Evaluation Accuracy:**
* REINFORCE: Starts at approximately 0.1, increases to around 0.75 by step 50, and remains relatively stable around 0.7-0.8.
* REC-OneSide-NoIS (0.6, 2.0): Starts at approximately 0.1, increases to around 0.7 by step 50, and remains relatively stable around 0.7-0.8.
* OPMD: Starts at approximately 0.2, increases steadily to around 0.75 by step 150.
* AsymRE (-0.1): Starts at approximately 0.2, increases to around 0.6 by step 50, then decreases to around 0.4 by step 100, and recovers slightly to around 0.5 by step 150.
* **Training Reward:**
* REINFORCE: Exhibits significant fluctuations, starting around 0.3, dropping to near 0 at step 25, and then oscillating between 0.2 and 0.6.
* REC-OneSide-NoIS (0.6, 2.0): Starts around 0.3, drops to near 0 at step 25, and then oscillates between 0.2 and 0.6.
* OPMD: Remains relatively stable around 0.7-0.8 throughout the training process.
* AsymRE (-0.1): Starts around 0.4, drops to near 0 at step 25, and then oscillates between 0.2 and 0.6.
**Column 3: `offline`**
* **Evaluation Accuracy:**
* REINFORCE: Starts at approximately 0.2, increases to around 0.7 by step 50, and remains relatively stable around 0.7-0.8.
* REC-OneSide-NoIS (0.6, 2.0): Starts at approximately 0.2, increases to around 0.7 by step 50, and remains relatively stable around 0.7-0.8.
* OPMD: Starts at approximately 0.3, increases steadily to around 0.7 by step 150.
* AsymRE (-0.1): Starts at approximately 0.3, increases to around 0.6 by step 50, then decreases to around 0.4 by step 100, and recovers slightly to around 0.5 by step 150.
* **Training Reward:**
* REINFORCE: Exhibits significant fluctuations, starting around 0.3, dropping to near 0 at step 25, and then oscillating between 0.2 and 0.6.
* REC-OneSide-NoIS (0.6, 2.0): Starts around 0.3, drops to near 0 at step 25, and then oscillates between 0.2 and 0.6.
* OPMD: Remains relatively stable around 0.7-0.8 throughout the training process.
* AsymRE (-0.1): Starts around 0.4, drops to near 0 at step 25, and then oscillates between 0.2 and 0.6.
### Key Observations
* OPMD consistently demonstrates the highest and most stable training reward across all synchronization conditions.
* REINFORCE and REC-OneSide-NoIS (0.6, 2.0) exhibit similar performance in terms of evaluation accuracy, generally achieving high scores but with more fluctuations in training reward.
* AsymRE (-0.1) shows the most volatile performance, with significant drops in both evaluation accuracy and training reward at certain points during training.
* The `sync_interval` and `sync_offset` conditions appear to yield similar results, while the `offline` condition shows slightly different initial performance.
### Interpretation
The data suggests that OPMD is the most robust and reliable algorithm for this task, consistently achieving high training rewards and stable performance. REINFORCE and REC-OneSide-NoIS (0.6, 2.0) are competitive but exhibit more instability, particularly in their training rewards. AsymRE (-0.1) appears to be the least stable and potentially requires further tuning or optimization. The synchronization conditions have a minor impact on performance, but the overall trends remain consistent across all three settings. The initial drop in training reward for REINFORCE, REC-OneSide-NoIS, and AsymRE could indicate a period of exploration or adaptation before the algorithms converge towards a stable policy. The fluctuations in training reward suggest that these algorithms are sensitive to the specific training steps and may benefit from techniques to reduce variance.