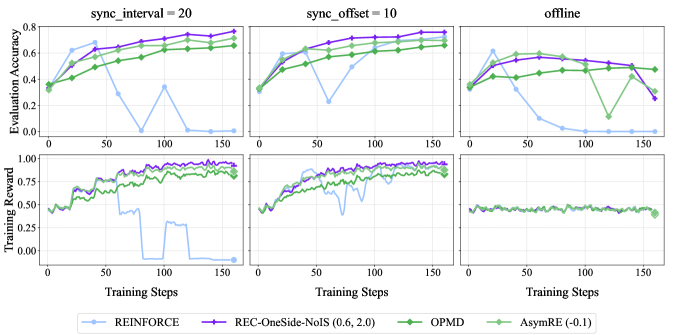
## Line Graphs: Evaluation Accuracy and Training Reward Across Training Steps
### Overview
The image contains six line graphs arranged in two rows (three graphs per row) comparing the performance of four reinforcement learning methods: **REINFORCE**, **REC-OneSide-NoIS (0.6, 2.0)**, **OPMD**, and **AsymRE (-0.1)**. The graphs are categorized by three scenarios:
1. **sync_interval = 20** (top-left)
2. **sync_offset = 10** (top-right)
3. **offline** (bottom row, shared across all methods)
Each graph tracks two metrics:
- **Evaluation Accuracy** (top subplot)
- **Training Reward** (bottom subplot)
### Components/Axes
- **X-axis**: Training Steps (0 to 150, increments of 50)
- **Y-axis (Top)**: Evaluation Accuracy (0 to 1.0)
- **Y-axis (Bottom)**: Training Reward (0 to 1.0)
- **Legend**: Located at the bottom of all graphs, with colors:
- **Blue**: REINFORCE
- **Purple**: REC-OneSide-NoIS (0.6, 2.0)
- **Green**: OPMD
- **Light Green**: AsymRE (-0.1)
### Detailed Analysis
#### **sync_interval = 20** (Top-Left)
- **Evaluation Accuracy**:
- **REINFORCE (Blue)**: Starts at ~0.3, dips to ~0.0 at 50 steps, then rises to ~0.6 by 150 steps.
- **REC-OneSide-NoIS (Purple)**: Steady increase from ~0.4 to ~0.8.
- **OPMD (Green)**: Gradual rise from ~0.3 to ~0.6.
- **AsymRE (Light Green)**: Fluctuates between ~0.4 and ~0.7, ending at ~0.7.
- **Training Reward**:
- **REINFORCE (Blue)**: Peaks at ~0.8 at 50 steps, then drops to ~0.0 by 150 steps.
- **REC-OneSide-NoIS (Purple)**: Stable increase from ~0.5 to ~0.9.
- **OPMD (Green)**: Gradual rise from ~0.4 to ~0.7.
- **AsymRE (Light Green)**: Stable ~0.6–0.7.
#### **sync_offset = 10** (Top-Right)
- **Evaluation Accuracy**:
- **REINFORCE (Blue)**: Starts at ~0.3, dips to ~0.1 at 50 steps, then rises to ~0.6.
- **REC-OneSide-NoIS (Purple)**: Steady increase from ~0.4 to ~0.8.
- **OPMD (Green)**: Gradual rise from ~0.3 to ~0.6.
- **AsymRE (Light Green)**: Fluctuates between ~0.4 and ~0.7, ending at ~0.7.
- **Training Reward**:
- **REINFORCE (Blue)**: Peaks at ~0.8 at 50 steps, then drops to ~0.2 by 150 steps.
- **REC-OneSide-NoIS (Purple)**: Stable increase from ~0.5 to ~0.9.
- **OPMD (Green)**: Gradual rise from ~0.4 to ~0.7.
- **AsymRE (Light Green)**: Stable ~0.6–0.7.
#### **offline** (Bottom Row, Shared Across All Methods)
- **Evaluation Accuracy**:
- **REINFORCE (Blue)**: Starts at ~0.3, dips to ~0.1 at 50 steps, then rises to ~0.4.
- **REC-OneSide-NoIS (Purple)**: Stable ~0.5–0.6.
- **OPMD (Green)**: Stable ~0.4–0.5.
- **AsymRE (Light Green)**: Stable ~0.5–0.6.
- **Training Reward**:
- **REINFORCE (Blue)**: Peaks at ~0.8 at 50 steps, then drops to ~0.2 by 150 steps.
- **REC-OneSide-NoIS (Purple)**: Stable ~0.6–0.7.
- **OPMD (Green)**: Stable ~0.5–0.6.
- **AsymRE (Light Green)**: Stable ~0.6–0.7.
### Key Observations
1. **REC-OneSide-NoIS (Purple)** consistently achieves the highest **Evaluation Accuracy** across all scenarios, with minimal fluctuations.
2. **REINFORCE (Blue)** shows significant volatility, with sharp drops in **Training Reward** (e.g., ~0.8 → 0.0 in sync_interval=20).
3. **AsymRE (-0.1)** (Light Green) maintains moderate performance but exhibits instability in **Training Reward** (e.g., dips to ~0.3 in sync_interval=20).
4. **OPMD (Green)** demonstrates steady but suboptimal performance compared to REC-OneSide-NoIS.
5. In the **offline** scenario, all methods underperform compared to synchronized settings, with **REINFORCE** showing the largest drop in **Training Reward**.
### Interpretation
- **REC-OneSide-NoIS (0.6, 2.0)** emerges as the most robust method, maintaining high **Evaluation Accuracy** and **Training Reward** across all scenarios. Its stability suggests superior adaptability to synchronization parameters.
- **REINFORCE**'s volatility indicates sensitivity to hyperparameters or environment dynamics, particularly in synchronized settings. The sharp drop in **Training Reward** at 50 steps (e.g., sync_interval=20) may reflect catastrophic forgetting or optimization instability.
- **AsymRE (-0.1)**'s fluctuating performance suggests potential trade-offs between exploration and exploitation, with inconsistent rewards despite moderate accuracy.
- The **offline** scenario highlights the importance of synchronization: all methods underperform, but **REINFORCE** is disproportionately affected, possibly due to reliance on external feedback loops.
This analysis underscores the critical role of synchronization strategies in reinforcement learning, with REC-OneSide-NoIS offering the most reliable performance.