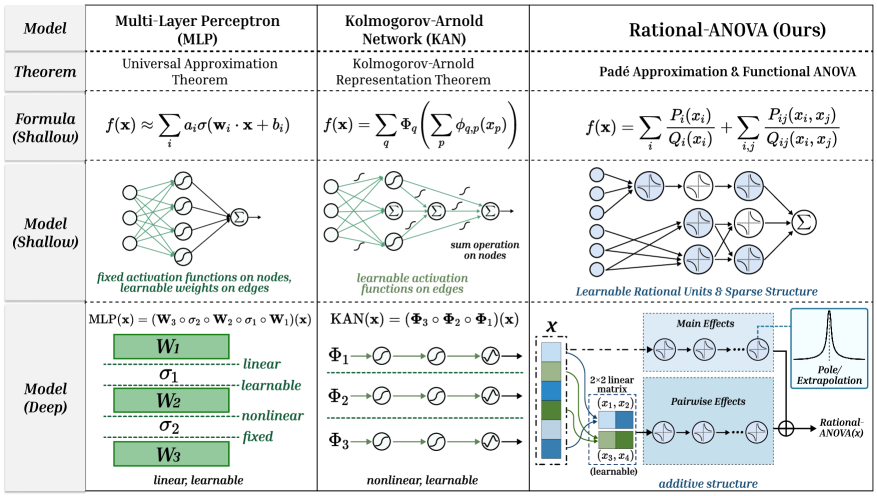
# Technical Document Extraction: Model Comparison Table
## Structure Overview
The image presents a comparative analysis of three computational models across four hierarchical sections:
1. **Model** (Header)
2. **Theorem** (Second row)
3. **Formula (Shallow)** (Third row)
4. **Model (Shallow)** (Fourth row)
5. **Model (Deep)** (Fifth row)
---
## Model-Specific Details
### 1. Multi-Layer Perceptron (MLP)
#### Theorem
- **Universal Approximation Theorem**
#### Formula (Shallow)
- \( f(\mathbf{x}) \approx \sum_i a_i\sigma(\mathbf{w}_i \cdot \mathbf{x} + b_i) \)
#### Model (Shallow)
- **Components**:
- Fixed activation functions on nodes
- Learnable weights on edges
- **Diagram**:
- Fully connected network with summation node
- Activation functions represented by σ symbols
#### Model (Deep)
- **Architecture**:
- Three layers (W₁, W₂, W₃)
- **Layer Properties**:
- W₁: Linear, learnable
- σ₁: Nonlinear, learnable
- W₂: Nonlinear, fixed
- σ₂: Nonlinear, fixed
- W₃: Linear, learnable
- **Formula**:
- \( \text{MLP}(\mathbf{x}) = (\mathbf{W}_3 \circ \sigma_2 \circ \mathbf{W}_2 \circ \sigma_1 \circ \mathbf{W}_1)(\mathbf{x}) \)
---
### 2. Kolmogorov-Arnold Network (KAN)
#### Theorem
- **Kolmogorov-Arnold Representation Theorem**
#### Formula (Shallow)
- \( f(\mathbf{x}) = \sum_q \Phi_q \left( \sum_p \phi_{q,p}(x_p) \right) \)
#### Model (Shallow)
- **Components**:
- Learnable activation functions on edges
- Sum operation on nodes
- **Diagram**:
- Nodes with Φ symbols
- Edge-based activation functions
#### Model (Deep)
- **Architecture**:
- Three sequential functions (Φ₁, Φ₂, Φ₃)
- **Function Properties**:
- Φ₁: Nonlinear, learnable
- Φ₂: Nonlinear, learnable
- Φ₃: Nonlinear, learnable
- **Formula**:
- \( \text{KAN}(\mathbf{x}) = (\Phi_3 \circ \Phi_2 \circ \Phi_1)(\mathbf{x}) \)
---
### 3. Rational-ANOVA (Ours)
#### Theorem
- **Padé Approximation & Functional ANOVA**
#### Formula (Shallow)
- \( f(\mathbf{x}) = \sum_i \frac{P_i(x_i)}{Q_i(x_i)} + \sum_{i,j} \frac{P_{ij}(x_i, x_j)}{Q_{ij}(x_i, x_j)} \)
#### Model (Shallow)
- **Components**:
- Learnable rational units
- Sparse structure
- **Diagram**:
- Nodes with rational function symbols
- Additive structure representation
#### Model (Deep)
- **Architecture**:
- **Main Effects**:
- 2D linear matrix (x₁, x₂)
- **Pairwise Effects**:
- 3D tensor (x₁, x₂, x₃)
- **Additive Structure**:
- Rational-ANOVA(x) with extrapolation component
- **Key Features**:
- Pole/Extrapolation handling
- Sparse connectivity pattern
---
## Diagram Component Analysis
### Spatial Grounding of Elements
1. **Legend Position**: Not explicitly visible in table format
2. **Color Coding**:
- MLP: Blue tones (W₁, W₂, W₃ blocks)
- KAN: Green tones (Φ₁, Φ₂, Φ₃ symbols)
- Rational-ANOVA: Red tones (rational function symbols)
### Trend Verification
- **MLP**: Layer complexity increases from shallow to deep
- **KAN**: Sequential function composition pattern
- **Rational-ANOVA**: Hierarchical effect decomposition (main → pairwise → extrapolation)
---
## Language Analysis
- **Primary Language**: English
- **Secondary Elements**:
- Mathematical notation (LaTeX)
- Technical terminology (ANOVA, perceptron, etc.)
---
## Data Table Reconstruction
| Model | Theorem | Formula (Shallow) | Model (Shallow) Components | Model (Deep) Architecture |
|----------------------|----------------------------------|-----------------------------------------------------------------------------------|-----------------------------------------------------|-------------------------------------------------------------------------------------------|
| Multi-Layer Perceptron (MLP) | Universal Approximation Theorem | \( f(\mathbf{x}) \approx \sum_i a_i\sigma(\mathbf{w}_i \cdot \mathbf{x} + b_i) \) | Fixed activations, learnable weights | 3-layer network with mixed linear/nonlinear functions |
| Kolmogorov-Arnold Network (KAN) | Kolmogorov-Arnold Representation Theorem | \( f(\mathbf{x}) = \sum_q \Phi_q \left( \sum_p \phi_{q,p}(x_p) \right) \) | Learnable edge activations, node summation | 3 sequential nonlinear learnable functions |
| Rational-ANOVA (Ours) | Padé Approximation & Functional ANOVA | \( f(\mathbf{x}) = \sum_i \frac{P_i(x_i)}{Q_i(x_i)} + \sum_{i,j} \frac{P_{ij}(x_i, x_j)}{Q_{ij}(x_i, x_j)} \) | Learnable rational units, sparse structure | Main effects (2D), pairwise effects (3D), extrapolation component |
---
## Critical Observations
1. **Functional Complexity**:
- MLP: Fixed nonlinearities with learnable weights
- KAN: Entirely learnable nonlinear functions
- Rational-ANOVA: Hybrid learnable rational functions with explicit effect decomposition
2. **Structural Differences**:
- MLP: Dense connectivity
- KAN: Sequential function composition
- Rational-ANOVA: Sparse additive structure with rational basis functions
3. **Theoretical Foundations**:
- MLP: Universal approximation guarantees
- KAN: Kolmogorov-Arnold representation
- Rational-ANOVA: Padé approximation theory combined with ANOVA decomposition