## Bar Chart: MakeMeSay vs GPT-4o Success Rate
### Overview
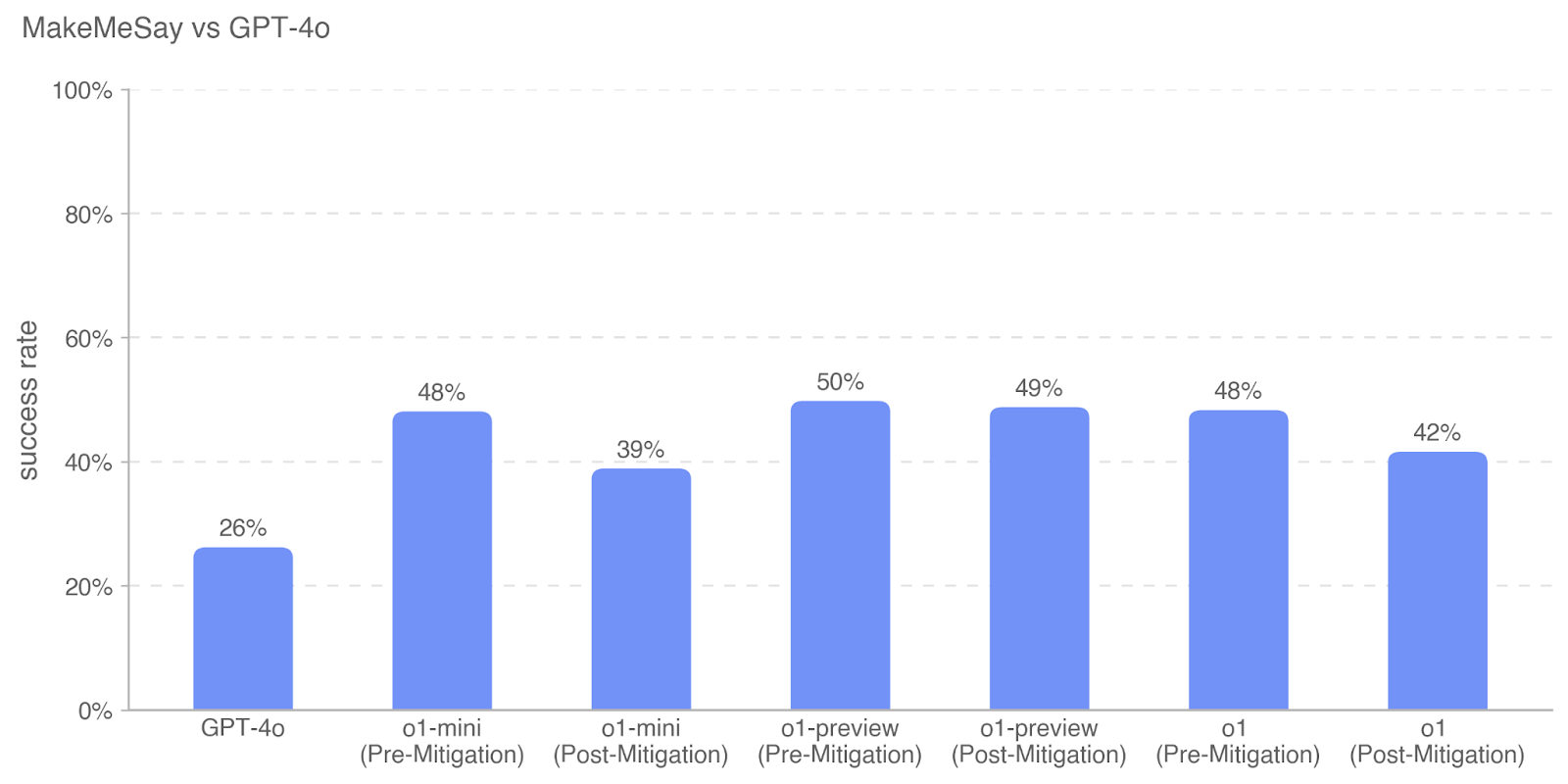
This bar chart compares the success rate of "MakeMeSay" against GPT-4o across several model variations, including pre- and post-mitigation stages. The success rate is measured as a percentage, ranging from 0% to 100%.
### Components/Axes
* **Title:** MakeMeSay vs GPT-4o
* **X-axis:** Model Variation (GPT-4o, o1-mini (Pre-Mitigation), o1-mini (Post-Mitigation), o1-preview (Pre-Mitigation), o1-preview (Post-Mitigation), o1 (Pre-Mitigation), o1 (Post-Mitigation))
* **Y-axis:** Success Rate (0% to 100%, with tick marks at 0%, 20%, 40%, 60%, 80%, and 100%)
* **Data Series:** Single series representing the success rate for each model variation.
* **Color:** All bars are a consistent light blue color.
* **Gridlines:** Horizontal dashed gray lines at 20%, 40%, 60%, and 80% on the Y-axis.
### Detailed Analysis
The chart displays the success rate for each model variation as a vertical bar.
* **GPT-4o:** The success rate is approximately 26%.
* **o1-mini (Pre-Mitigation):** The success rate is approximately 48%.
* **o1-mini (Post-Mitigation):** The success rate is approximately 39%.
* **o1-preview (Pre-Mitigation):** The success rate is approximately 50%.
* **o1-preview (Post-Mitigation):** The success rate is approximately 49%.
* **o1 (Pre-Mitigation):** The success rate is approximately 48%.
* **o1 (Post-Mitigation):** The success rate is approximately 42%.
The bars representing "o1-mini (Pre-Mitigation)" and "o1 (Pre-Mitigation)" are of equal height. The bars representing "o1-preview (Pre-Mitigation)" and "o1-preview (Post-Mitigation)" are also very close in height.
### Key Observations
* GPT-4o has the lowest success rate among all models tested.
* The "Pre-Mitigation" versions of o1-mini, o1-preview, and o1 all exhibit higher success rates than their "Post-Mitigation" counterparts.
* The success rate for o1-mini decreases after mitigation.
* The success rate for o1-preview remains relatively stable after mitigation.
* The success rate for o1 decreases after mitigation.
### Interpretation
The data suggests that the "MakeMeSay" model generally outperforms GPT-4o in terms of success rate, particularly in its pre-mitigation versions. The mitigation process appears to negatively impact the success rate of o1-mini and o1, while having a minimal effect on o1-preview. This could indicate that the mitigation strategies employed are more effective for certain model architectures than others. The consistent success rate of o1-preview before and after mitigation suggests that this model may be less susceptible to the issues that the mitigation process is intended to address. The lower success rate of GPT-4o compared to all other models suggests that it may require further optimization or different mitigation strategies to achieve comparable performance. The data highlights the importance of considering the impact of mitigation techniques on model performance and tailoring these techniques to specific model characteristics.