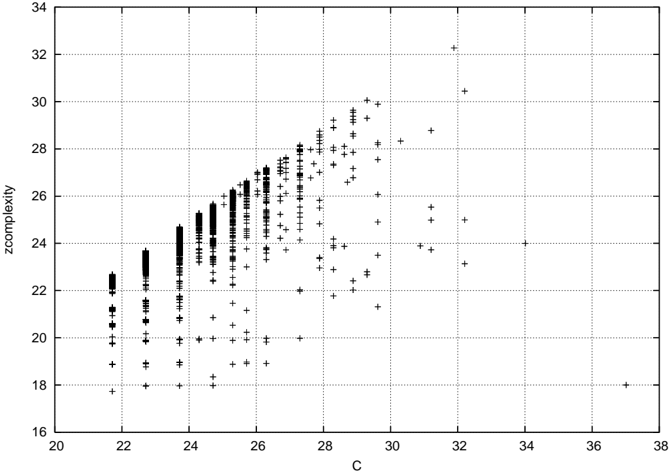
## Scatter Plot: Relationship Between C and zcomplexity
### Overview
The image is a scatter plot with a grid background, displaying data points as black squares and plus signs. The x-axis is labeled "C" (ranging from 20 to 38), and the y-axis is labeled "zcomplexity" (ranging from 16 to 34). The data points are distributed across the plot, with distinct clustering patterns.
### Components/Axes
- **X-axis (C)**: Labeled "C", with tick marks at intervals of 2 (20, 22, 24, ..., 38).
- **Y-axis (zcomplexity)**: Labeled "zcomplexity", with tick marks at intervals of 2 (16, 18, 20, ..., 34).
- **Grid**: Dotted lines form a grid to aid in reading values.
- **Data Points**:
- **Black squares**: Clustered in the lower-left region (C ≈ 20–25, zcomplexity ≈ 18–24).
- **Plus signs**: Scattered across the plot, with higher density in the upper-right region (C ≈ 25–38, zcomplexity ≈ 24–32).
- **Legend**: Not visible in the image.
### Detailed Analysis
- **Black squares**:
- Concentrated between C = 20–25 and zcomplexity = 18–24.
- Some outliers extend slightly to C = 26–28 and zcomplexity = 22–26.
- **Plus signs**:
- Spread across C = 25–38 and zcomplexity = 24–32.
- Notable outliers:
- A single plus at (C = 36, zcomplexity = 18).
- A cluster of pluses near (C = 28–30, zcomplexity = 26–28).
- **Distribution**:
- Lower-left region (C < 25, zcomplexity < 24) dominated by squares.
- Upper-right region (C > 25, zcomplexity > 24) dominated by pluses.
### Key Observations
1. **Clustering**: The black squares form a dense cluster in the lower-left, suggesting a potential relationship between lower C values and lower zcomplexity.
2. **Spread**: The plus signs are more dispersed, indicating variability in zcomplexity for higher C values.
3. **Outliers**: The plus at (36, 18) is an anomaly, as it deviates from the general trend of higher zcomplexity with increasing C.
4. **No Legend**: The absence of a legend leaves the meaning of the symbols (squares vs. pluses) ambiguous.
### Interpretation
The data suggests a possible inverse relationship between C and zcomplexity in the lower range (C < 25), where lower C values correspond to lower zcomplexity. However, for higher C values (C > 25), zcomplexity increases but with greater variability, as indicated by the spread of plus signs. The outlier at (36, 18) may represent an exception or a data point from a different category. Without a legend, the distinction between squares and pluses remains unclear, but their spatial distribution implies two distinct groups or conditions. Further context is needed to confirm the nature of the relationship and the significance of the symbols.