\n
## Diagram: CoMeT Commonsense Transformers Architecture
### Overview
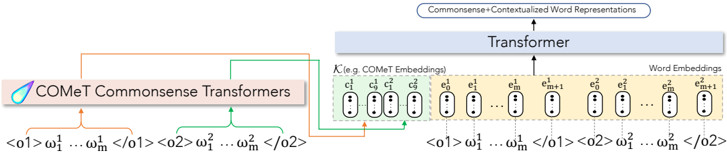
The image depicts a diagram illustrating the architecture of CoMeT (Commonsense Transformers). It shows how input tokens are processed through the CoMeT model to generate embeddings, which are then fed into a Transformer to produce contextualized word representations. The diagram highlights the input token sequences, CoMeT embeddings, and the final output.
### Components/Axes
The diagram consists of the following key components:
* **CoMeT Commonsense Transformers:** A purple rectangular block labeled "CoMeT Commonsense Transformers".
* **Input Token Sequences:** Two sequences of tokens represented as `<01> ω₁¹ ... ωₘ¹ <02>` and `<02> ω₁² ... ωₘ² <02>`.
* **CoMeT Embeddings:** A series of oval shapes labeled `c₁`, `c₂`, ..., `cₘ`, `cₘ+1`, `e₁`, `e₂`, ..., `eₘ`, `eₘ+1`. These are grouped under the label "K (e.g. CoMeT Embeddings)".
* **Word Embeddings:** A series of oval shapes labeled `e₁`, `e₂`, ..., `eₘ`, `eₘ+1`.
* **Transformer:** A large light blue rectangular block labeled "Transformer".
* **Output:** A rectangular block labeled "Commonsense + Contextualized Word Representations".
* **Arrows:** Arrows indicating the flow of data between the components.
### Detailed Analysis or Content Details
The diagram illustrates the following process:
1. **Input:** Two sequences of tokens, `<01> ω₁¹ ... ωₘ¹ <02>` and `<02> ω₁² ... ωₘ² <02>`, are provided as input. The `<01>` and `<02>` likely represent start and end tokens, and ω represents the individual tokens.
2. **CoMeT Processing:** These input sequences are fed into the "CoMeT Commonsense Transformers" block.
3. **Embedding Generation:** The CoMeT model generates a series of embeddings, represented as `c₁`, `c₂`, ..., `cₘ`, `cₘ+1` and `e₁`, `e₂`, ..., `eₘ`, `eₘ+1`. The `c` embeddings are labeled as "CoMeT Embeddings" and the `e` embeddings are labeled as "Word Embeddings".
4. **Transformer Input:** The CoMeT embeddings are then fed into the "Transformer" block.
5. **Contextualization:** The Transformer processes the embeddings to generate "Commonsense + Contextualized Word Representations" as output.
The diagram shows a parallel processing of two input sequences, with the CoMeT model generating embeddings for both. The embeddings are then combined and fed into the Transformer. The number of embeddings (m+1) is consistent across both input sequences.
### Key Observations
* The diagram emphasizes the role of CoMeT in generating embeddings that capture commonsense knowledge.
* The Transformer is depicted as a central component for contextualizing the embeddings.
* The use of two input sequences suggests that CoMeT may be designed to handle multiple perspectives or contexts.
* The diagram does not provide specific details about the internal workings of the CoMeT model or the Transformer.
### Interpretation
The diagram illustrates a pipeline for incorporating commonsense knowledge into word representations. The CoMeT model acts as a knowledge encoder, transforming input tokens into embeddings that capture relevant commonsense information. These embeddings are then fed into a Transformer, which leverages its attention mechanism to contextualize the embeddings and generate more informative word representations. This approach aims to improve the performance of downstream NLP tasks that require commonsense reasoning. The parallel processing of two input sequences suggests that CoMeT may be capable of handling ambiguous or multi-faceted inputs, allowing it to generate more robust and nuanced representations. The diagram is a high-level overview and does not delve into the specific algorithms or parameters used in the CoMeT model or the Transformer. It serves as a conceptual illustration of the overall architecture and data flow.