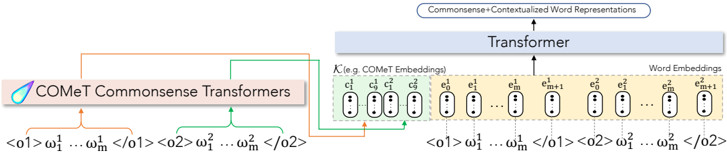
## System Architecture Diagram: COMeT-Enhanced Transformer for Commonsense Representations
### Overview
This image is a technical system architecture diagram illustrating a natural language processing model that integrates commonsense knowledge into contextualized word representations. The diagram shows the flow of data from input sequences through a specialized commonsense module (COMeT) and a standard embedding layer, which are then combined and processed by a Transformer to produce enriched output representations.
### Components/Axes
The diagram is composed of three primary functional blocks connected by directional arrows indicating data flow:
1. **Left Block: COMeT Commonsense Transformers**
* **Label:** "COMeT Commonsense Transformers" (with a stylized droplet logo).
* **Input:** Two example input sequences are shown below the block:
* `<o1> ω₁¹ ... ωₘ¹ </o1>`
* `<o2> ω₁² ... ωₘ² </o2>`
* **Output:** Two arrows originate from this block:
* An **orange arrow** points to the "Transformer" block.
* A **green arrow** points to the "COMeT Embeddings" section within the "Word Embeddings" block.
2. **Right Block: Word Embeddings**
* **Main Label:** "Word Embeddings" (positioned above the right half of the block).
* **Sub-section 1 (Left):** Labeled "(e.g., COMeT Embeddings)". It contains a series of oval shapes representing embedding vectors, labeled:
* `c₁¹`, `c₂¹`, `c₃¹`, `cₘ¹`
* **Sub-section 2 (Right):** Contains another series of oval shapes representing standard word embedding vectors, labeled:
* `e₁¹`, `e₂¹`, `eₘ¹`, `e₁²`, `e₂²`, `eₘ²`, `eₘ₊₁²`
* **Input:** The same two input sequences from the left block are repeated below this block, aligned with the embedding vectors:
* `<o1> ω₁¹ ... ωₘ¹ </o1>`
* `<o2> ω₁² ... ωₘ² </o2>`
* **Output:** A single black arrow points upward from this entire block to the "Transformer".
3. **Top Block: Transformer**
* **Label:** "Transformer".
* **Input:** Receives combined input from both the COMeT block (orange arrow) and the Word Embeddings block (black arrow).
* **Output:** A single arrow points upward to the final output label: "Commonsense+Contextualized Word Representations".
### Detailed Analysis
* **Data Flow & Integration:** The diagram explicitly shows two parallel pathways for enriching word representations:
* **Commonsense Pathway:** Input sequences (`<o1>`, `<o2>`) are processed by the "COMeT Commonsense Transformers" module. This generates specialized "COMeT Embeddings" (`c` vectors), which are fed into the main Transformer.
* **Contextual Pathway:** The same input sequences are used to generate standard "Word Embeddings" (`e` vectors). These are also fed into the main Transformer.
* **Component Relationships:** The "Transformer" block acts as the central fusion unit. It receives and integrates the commonsense knowledge (via the orange arrow and COMeT embeddings) with the standard contextual word embeddings (via the black arrow) to produce the final, hybrid output.
* **Notation:** The notation uses superscripts to denote sequence index (e.g., `ω₁¹` is the first token of the first sequence `<o1>`) and subscripts for position within the sequence. The `c` and `e` prefixes distinguish between COMeT-derived and standard word embeddings.
### Key Observations
* **Dual Embedding Source:** The architecture is defined by its use of two distinct embedding sources (`c` and `e`) for the same input tokens, which are processed jointly.
* **Asymmetric Flow:** The COMeT module has a direct connection to the Transformer (orange arrow) *and* contributes to the Word Embeddings block (green arrow), indicating it plays a foundational role in the embedding generation process itself.
* **Output Specificity:** The final output is explicitly labeled as "Commonsense+Contextualized," highlighting the model's intended purpose of merging these two types of information.
### Interpretation
This diagram represents a **knowledge-enhanced neural architecture** for natural language understanding. The core innovation is the integration of a dedicated commonsense reasoning module (COMeT) into the standard Transformer-based embedding pipeline.
* **What it demonstrates:** The model aims to solve a key limitation of standard language models by explicitly injecting structured commonsense knowledge (e.g., "a dog is a pet," "fire is hot") into the representation of words. This is achieved by generating separate commonsense embeddings (`c` vectors) that are then fused with contextual embeddings (`e` vectors) inside the Transformer.
* **How elements relate:** The COMeT module acts as a knowledge base or reasoner. It doesn't just look at the word in its sentence context; it also retrieves or generates associated commonsense facts. The Transformer's job is to learn how to best combine these two complementary signals—the contextual meaning from the text and the external commonsense knowledge—into a single, more robust representation.
* **Significance:** Such an architecture would be particularly valuable for tasks requiring deep inference and real-world knowledge, such as question answering, story understanding, or dialogue systems, where understanding implied facts is crucial. The diagram visually argues that superior "Commonsense+Contextualized" representations require this explicit, parallel processing of knowledge and context.