## Diagram: LLM-Based Query Processing Architectures (PaG)
### Overview
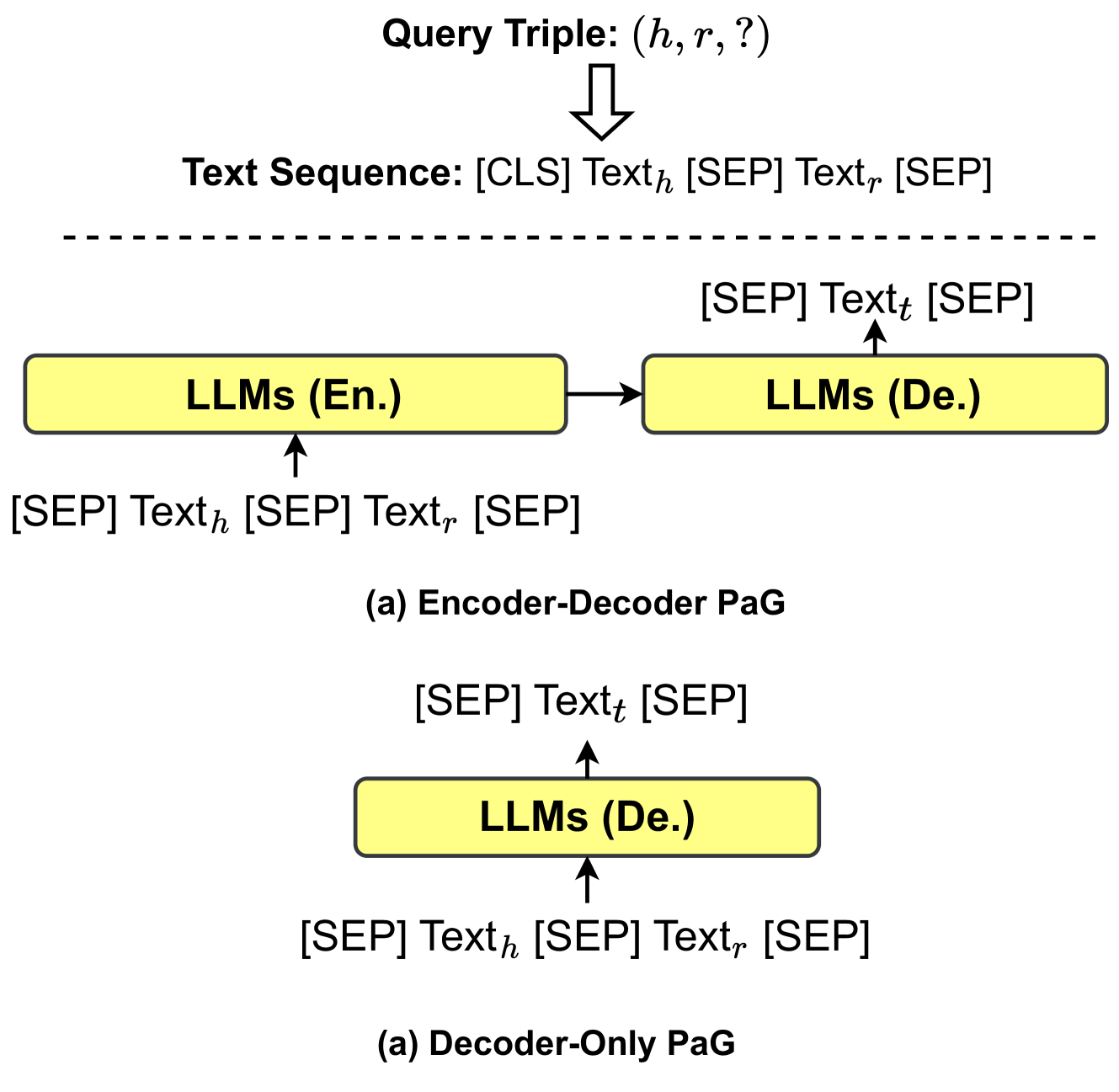
The image is a technical diagram illustrating two different architectures for processing a knowledge graph query triple using Large Language Models (LLMs). The architectures are labeled as "Encoder-Decoder PaG" and "Decoder-Only PaG". The diagram shows the flow of data from an input query triple through text sequence formatting and into the LLM components.
### Components/Axes
The diagram is divided into two main sections, separated by a horizontal dashed line.
**Top Section (Input Preparation):**
* **Top Center:** Text label "Query Triple: (h, r, ?)". An arrow points downward from this label.
* **Below Arrow:** Text label "Text Sequence: [CLS] Textₕ [SEP] Textᵣ [SEP]". This represents the formatted input sequence derived from the query triple.
**Middle Section (Encoder-Decoder PaG):**
* **Label:** "(a) Encoder-Decoder PaG" is centered below this section.
* **Components:**
* A yellow rectangular box labeled "LLMs (En.)" (Encoder).
* A second yellow rectangular box to its right labeled "LLMs (De.)" (Decoder).
* A rightward-pointing arrow connects the "LLMs (En.)" box to the "LLMs (De.)" box.
* **Data Flow:**
* An upward arrow points into the bottom of the "LLMs (En.)" box. The associated text is: "[SEP] Textₕ [SEP] Textᵣ [SEP]".
* An upward arrow points out of the top of the "LLMs (De.)" box. The associated text is: "[SEP] Textₜ [SEP]".
**Bottom Section (Decoder-Only PaG):**
* **Label:** "(a) Decoder-Only PaG" is centered below this section. *(Note: The label is identical to the one above, which may be a typographical error in the source image.)*
* **Components:**
* A single yellow rectangular box labeled "LLMs (De.)".
* **Data Flow:**
* An upward arrow points into the bottom of the "LLMs (De.)" box. The associated text is: "[SEP] Textₕ [SEP] Textᵣ [SEP]".
* An upward arrow points out of the top of the "LLMs (De.)" box. The associated text is: "[SEP] Textₜ [SEP]".
### Detailed Analysis
The diagram details the data transformation and model flow for two approaches to a task abbreviated as "PaG" (likely "Prompt-as-Graph" or similar).
1. **Input:** The process begins with a "Query Triple" in the form `(h, r, ?)`, which is a standard knowledge graph query where `h` is the head entity, `r` is the relation, and `?` denotes the missing tail entity to be predicted.
2. **Textualization:** This triple is converted into a "Text Sequence" using special tokens: `[CLS]` (classification token), `[SEP]` (separator token), `Textₕ` (text representation of the head entity), and `Textᵣ` (text representation of the relation).
3. **Encoder-Decoder PaG Architecture:**
* The formatted sequence `[SEP] Textₕ [SEP] Textᵣ [SEP]` is fed into an **Encoder** LLM (`LLMs (En.)`).
* The encoder's output is passed to a **Decoder** LLM (`LLMs (De.)`).
* The decoder generates the output sequence `[SEP] Textₜ [SEP]`, where `Textₜ` represents the predicted tail entity in text form.
4. **Decoder-Only PaG Architecture:**
* The same formatted sequence `[SEP] Textₕ [SEP] Textᵣ [SEP]` is fed directly into a single **Decoder-only** LLM (`LLMs (De.)`).
* This single model generates the same output sequence `[SEP] Textₜ [SEP]`.
### Key Observations
* **Architectural Contrast:** The core difference is the use of two specialized models (Encoder + Decoder) versus a single, unified Decoder-only model for the same task.
* **Input Consistency:** Both architectures receive an identical input text sequence derived from the query triple.
* **Output Consistency:** Both architectures are designed to produce an identical output format: a text sequence containing the predicted tail entity (`Textₜ`).
* **Labeling Anomaly:** Both architectural diagrams are labeled with "(a)", which is likely an error. Typically, they would be labeled (a) and (b) for distinction.
### Interpretation
This diagram illustrates a method for framing knowledge graph completion (predicting the tail entity `?` in a triple `(h, r, ?)`) as a text-to-text generation problem solvable by LLMs. The "PaG" approach involves converting the structured query into a natural language-like sequence.
The comparison highlights a significant design choice in applying LLMs:
* The **Encoder-Decoder** approach uses a dedicated encoder to understand the input query and a separate decoder to generate the answer, potentially allowing for more specialized processing.
* The **Decoder-Only** approach leverages the generative capabilities of a single model to perform both understanding and generation, which is characteristic of models like GPT.
The diagram suggests that the research or system being documented explores or utilizes both paradigms, possibly to compare their effectiveness or to offer flexibility based on the available LLM infrastructure. The consistent use of special tokens (`[CLS]`, `[SEP]`) indicates the use of a model architecture and tokenization scheme similar to BERT (for the encoder) or standard sequence-to-sequence models.