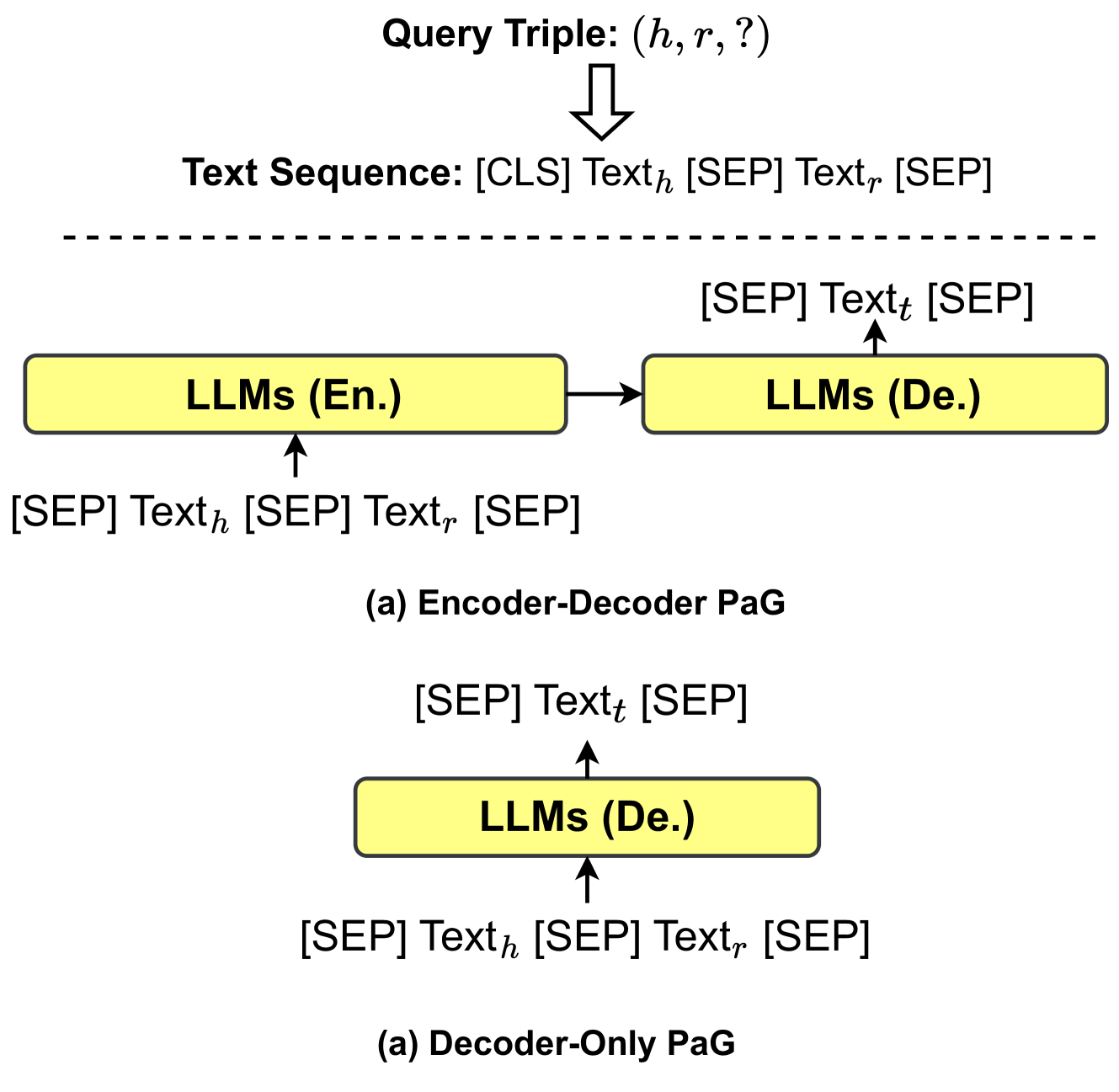
## Diagram: Text Processing Pipeline with LLMs
### Overview
The diagram illustrates two text processing pipelines using Large Language Models (LLMs):
1. **Encoder-Decoder PaG** (top section)
2. **Decoder-Only PaG** (bottom section)
Both pipelines process query triples `(h, r, ?)` and text sequences with special tokens (`[CLS]`, `[SEP]`). Arrows indicate data flow between components.
---
### Components/Axes
#### Header
- **Query Triple**: `(h, r, ?)`
- Represents a knowledge graph triple (head entity `h`, relation `r`, unknown tail `?`).
- **Text Sequence**: `[CLS] Text_h [SEP] Text_r [SEP]`
- Structured input for LLMs, with `[CLS]` for classification and `[SEP]` as separators.
#### Main Chart (Encoder-Decoder PaG)
1. **Encoder LLM (LLMs (En.))**
- Input: `[SEP] Text_h [SEP] Text_r [SEP]`
- Output: Embeddings for decoder.
2. **Decoder LLM (LLMs (De.))**
- Input: `[SEP] Text_t [SEP]` (target text).
- Output: Generated response.
- Arrows show sequential processing: Encoder → Decoder.
#### Main Chart (Decoder-Only PaG)
- **Decoder LLM (LLMs (De.))**
- Input: `[SEP] Text_h [SEP] Text_r [SEP]`
- Output: Direct generation without encoder.
---
### Detailed Analysis
#### Textual Elements
- **Special Tokens**:
- `[CLS]`: Marks start of sequence for classification tasks.
- `[SEP]`: Separates distinct text segments (e.g., `Text_h`, `Text_r`, `Text_t`).
- **Text Variables**:
- `Text_h`: Head entity description.
- `Text_r`: Relation description.
- `Text_t`: Target/tail entity (unknown in query triple).
#### Flow Direction
- **Encoder-Decoder PaG**:
- Encoder processes `Text_h` and `Text_r` to create contextual embeddings.
- Decoder uses these embeddings to generate `Text_t`.
- **Decoder-Only PaG**:
- Single LLM processes all input text (`Text_h`, `Text_r`) directly to predict `Text_t`.
---
### Key Observations
1. **Tokenization Consistency**:
- Both pipelines use identical tokenization (`[SEP]`, `[CLS]`), suggesting compatibility with transformer-based models (e.g., BERT, GPT).
2. **Architectural Difference**:
- Encoder-Decoder PaG separates encoding/decoding stages, while Decoder-Only PaG combines them.
3. **Input Structure**:
- Query triples and text sequences are tightly integrated, implying joint optimization for knowledge graph completion.
---
### Interpretation
- **Purpose**: The diagram demonstrates how LLMs handle structured knowledge graph queries.
- **Encoder-Decoder PaG**: Suitable for tasks requiring explicit encoding of relations (e.g., complex reasoning).
- **Decoder-Only PaG**: Simplifies the pipeline but may sacrifice relational context.
- **Implications**:
- The use of `[SEP]` tokens highlights the importance of segmenting input for model attention.
- The absence of an encoder in the Decoder-Only PaG suggests a trade-off between efficiency and relational modeling capability.
- **Anomalies**:
- No explicit handling of the unknown tail `?` in the query triple, implying it is inferred during decoding.
This diagram underscores the adaptability of LLMs to knowledge graph tasks, balancing architectural complexity with performance requirements.