## Bar Chart: Turkcell-LLM
### Overview
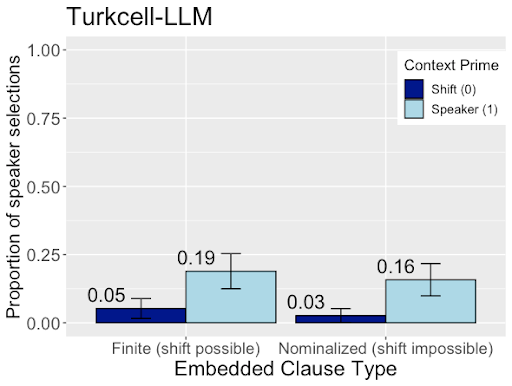
The image is a bar chart comparing the proportion of speaker selections for two types of embedded clauses (Finite and Nominalized) under two different context primes (Shift and Speaker). The chart displays the results for the Turkcell-LLM model. Error bars are included on each bar.
### Components/Axes
* **Title:** Turkcell-LLM
* **Y-axis:** Proportion of speaker selections, with a scale from 0.00 to 1.00 in increments of 0.25.
* **X-axis:** Embedded Clause Type, with two categories: "Finite (shift possible)" and "Nominalized (shift impossible)".
* **Legend (top-right):** Context Prime, with two categories:
* Shift (0) - represented by a dark blue bar.
* Speaker (1) - represented by a light blue bar.
### Detailed Analysis
* **Finite (shift possible) Clause:**
* Shift (0): Proportion of speaker selections is 0.05, dark blue bar.
* Speaker (1): Proportion of speaker selections is 0.19, light blue bar.
* **Nominalized (shift impossible) Clause:**
* Shift (0): Proportion of speaker selections is 0.03, dark blue bar.
* Speaker (1): Proportion of speaker selections is 0.16, light blue bar.
### Key Observations
* For both clause types, the "Speaker (1)" context prime results in a higher proportion of speaker selections compared to the "Shift (0)" context prime.
* The difference in proportion of speaker selections between "Speaker (1)" and "Shift (0)" is larger for the "Finite (shift possible)" clause type (0.19 vs 0.05) than for the "Nominalized (shift impossible)" clause type (0.16 vs 0.03).
* The error bars indicate the variability in the data.
### Interpretation
The data suggests that the Turkcell-LLM model is sensitive to the context prime when selecting speakers. Specifically, priming the model with the "Speaker (1)" context leads to a higher likelihood of selecting the speaker, regardless of the type of embedded clause. The difference in performance between the two context primes is more pronounced when the embedded clause allows for a shift in perspective ("Finite (shift possible)"). This could indicate that the model is better at integrating contextual information when the sentence structure allows for more flexibility in interpretation. The error bars provide a measure of the uncertainty associated with these observations.