\n
## Bar Chart: Turkcell-LLM Speaker Selection Proportion
### Overview
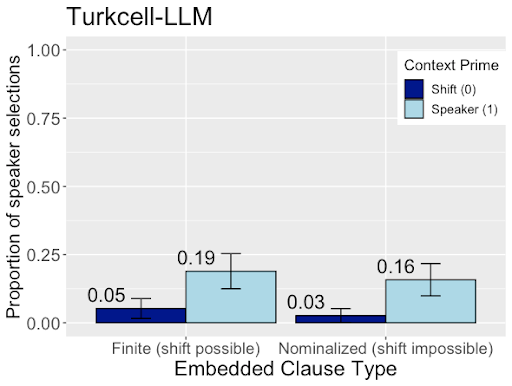
This bar chart visualizes the proportion of speaker selections for a Turkcell-LLM model, categorized by Embedded Clause Type and Context Prime. The chart displays the average proportion with error bars representing the variability.
### Components/Axes
* **Title:** Turkcell-LLM
* **X-axis:** Embedded Clause Type. Categories are: "Finite (shift possible)" and "Nominalized (shift impossible)".
* **Y-axis:** Proportion of speaker selections. Scale ranges from 0.00 to 1.00, with increments of 0.25.
* **Legend:** Located in the top-right corner.
* "Shift (0)" - Represented by dark blue color.
* "Speaker (1)" - Represented by light blue color.
### Detailed Analysis
The chart consists of two sets of bars for each Embedded Clause Type, representing the "Shift" and "Speaker" context primes. Error bars are present on top of each bar, indicating the standard error or confidence interval.
**Finite (shift possible):**
* **Shift (0):** The dark blue bar has a height of approximately 0.05, with an error bar extending slightly above 0.06.
* **Speaker (1):** The light blue bar has a height of approximately 0.19, with an error bar extending from approximately 0.16 to 0.22.
**Nominalized (shift impossible):**
* **Shift (0):** The dark blue bar has a height of approximately 0.03, with an error bar extending slightly above 0.04.
* **Speaker (1):** The light blue bar has a height of approximately 0.16, with an error bar extending from approximately 0.13 to 0.19.
### Key Observations
* For both clause types, the "Speaker" context prime (light blue) consistently shows a higher proportion of speaker selections than the "Shift" context prime (dark blue).
* The difference between the "Shift" and "Speaker" proportions is more pronounced for the "Finite (shift possible)" clause type than for the "Nominalized (shift impossible)" clause type.
* The error bars suggest that the differences observed are statistically significant, although the exact p-values are not provided.
### Interpretation
The data suggests that the Turkcell-LLM model is more likely to select the "Speaker" context prime when processing language, regardless of whether a shift in perspective is grammatically possible. The model appears to favor maintaining a consistent speaker perspective. The fact that the difference is more pronounced for "Finite (shift possible)" clauses indicates that the model is sensitive to the grammatical possibility of a shift, but still tends to prioritize the speaker context. This could be due to the model's training data or inherent biases in its architecture. The error bars provide a measure of the variability in the model's responses, suggesting that while there is a clear trend, individual responses may deviate from the average. Further investigation would be needed to determine the underlying reasons for these patterns and to assess the model's performance on other language tasks.