TECHNICAL ASSET FINGERPRINT
92b4e709b51de46497ed94fd
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
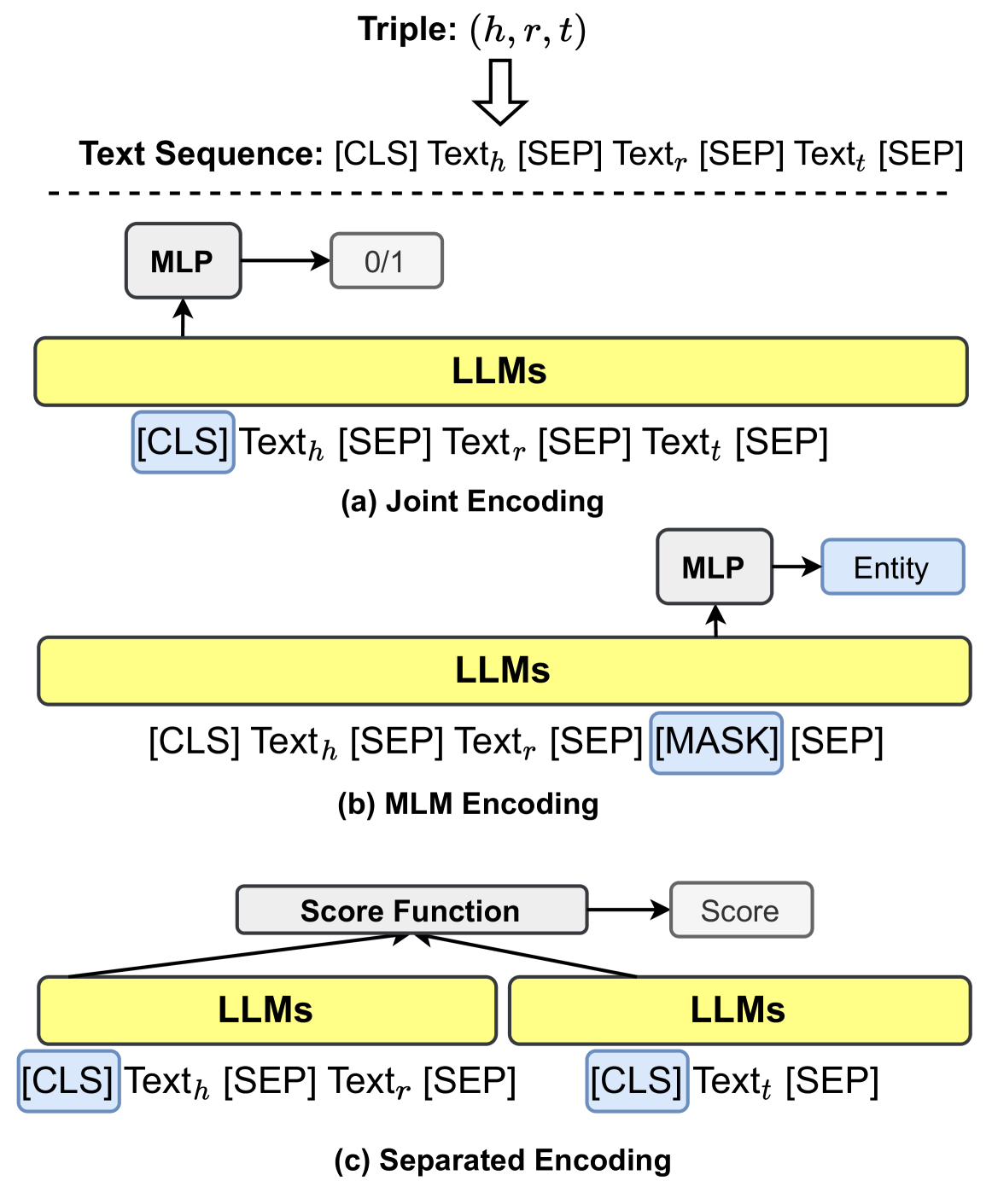
## Diagram: Knowledge Graph Triple Encoding Methods Using Large Language Models (LLMs)
### Overview
This image is a technical diagram illustrating three distinct methods for encoding knowledge graph triples, represented as (head, relation, tail) or (h, r, t), using Large Language Models (LLMs). The diagram is divided into three vertically stacked sections, each depicting a different encoding paradigm: (a) Joint Encoding, (b) MLM (Masked Language Model) Encoding, and (c) Separated Encoding. The overall flow shows how a structured triple is transformed into a text sequence and processed by an LLM-based architecture to produce a specific output (classification, entity prediction, or a score).
### Components/Axes
The diagram is composed of the following key components, arranged from top to bottom:
1. **Top Header (Common Input):**
* **Text:** `Triple: (h, r, t)`
* **Visual:** A downward-pointing arrow leads to the next line.
* **Text:** `Text Sequence: [CLS] Text_h [SEP] Text_r [SEP] Text_t [SEP]`
* **Visual:** A dashed horizontal line separates this common input definition from the three specific encoding methods below.
2. **Section (a) - Joint Encoding:**
* **Input Sequence:** `[CLS] Text_h [SEP] Text_r [SEP] Text_t [SEP]` (highlighted with a blue box around `[CLS]`).
* **Processing Block:** A yellow rectangle labeled `LLMs`.
* **Output Path:** An arrow points upward from the LLMs block to a white box labeled `MLP` (Multi-Layer Perceptron). An arrow from the MLP points to a final white box containing `0/1`, indicating a binary classification output.
* **Label:** `(a) Joint Encoding` is centered below this section.
3. **Section (b) - MLM Encoding:**
* **Input Sequence:** `[CLS] Text_h [SEP] Text_r [SEP] [MASK] [SEP]` (highlighted with a blue box around `[MASK]`).
* **Processing Block:** A yellow rectangle labeled `LLMs`.
* **Output Path:** An arrow points upward from the LLMs block to a white box labeled `MLP`. An arrow from the MLP points to a final light blue box labeled `Entity`.
* **Label:** `(b) MLM Encoding` is centered below this section.
4. **Section (c) - Separated Encoding:**
* **Input Sequences (Two Parallel Streams):**
* **Left Stream:** `[CLS] Text_h [SEP] Text_r [SEP]` (highlighted with a blue box around `[CLS]`).
* **Right Stream:** `[CLS] Text_t [SEP]` (highlighted with a blue box around `[CLS]`).
* **Processing Blocks:** Two separate yellow rectangles, each labeled `LLMs`, one for each input stream.
* **Output Path:** Arrows from both LLMs blocks converge upward into a white box labeled `Score Function`. An arrow from the Score Function points to a final white box labeled `Score`.
* **Label:** `(c) Separated Encoding` is centered below this section.
### Detailed Analysis
The diagram details the architectural flow for each method:
* **(a) Joint Encoding:** The entire triple, formatted as a single text sequence with separator tokens (`[SEP]`), is fed into an LLM. The representation of the special `[CLS]` token (typically used for sequence-level tasks) is passed to an MLP, which outputs a binary value (`0/1`). This suggests a task like triple classification (determining if the triple is true or false).
* **(b) MLM Encoding:** The input sequence is similar, but the tail entity text (`Text_t`) is replaced with a `[MASK]` token. The LLM processes this masked sequence. The representation at the position of the `[MASK]` token is fed to an MLP to predict the original `Entity` (i.e., `Text_t`). This is a classic masked language modeling objective applied to knowledge graph completion.
* **(c) Separated Encoding:** The head-relation pair (`Text_h`, `Text_r`) and the tail entity (`Text_t`) are encoded independently by two (potentially shared) LLMs. Each input starts with its own `[CLS]` token. The final hidden states corresponding to these `[CLS]` tokens are then combined by a `Score Function` to produce a scalar `Score`. This score likely measures the validity or plausibility of the triple (h, r, t).
### Key Observations
1. **Input Formatting Consistency:** All methods use the same foundational text sequence format: `[CLS] ... [SEP] ... [SEP] ... [SEP]`. The key variation is whether the tail is present (`Text_t`), masked (`[MASK]`), or processed separately.
2. **Special Token Utilization:** The `[CLS]` token is consistently used as the aggregate sequence representation for downstream tasks (classification in (a), and as input to the score function in (c)). In (b), the `[MASK]` token's position is used for prediction.
3. **Output Divergence:** The three methods are designed for different downstream tasks: binary classification (a), entity prediction/filling (b), and scoring/ranking (c).
4. **Architectural Complexity:** The complexity increases from (a) to (c). Joint Encoding uses a single LLM pass. MLM Encoding also uses a single pass but with a masked objective. Separated Encoding requires two parallel LLM passes and an additional fusion mechanism (Score Function).
### Interpretation
This diagram provides a comparative overview of how pre-trained LLMs can be adapted for knowledge graph reasoning tasks. It demonstrates the flexibility of the transformer architecture and the text-based interface for structured data.
* **What the data suggests:** The diagram suggests that knowledge graph triples can be effectively "linearized" into text sequences that LLMs are pre-trained to understand. The choice of encoding method depends on the specific task: verifying existing triples (Joint Encoding), predicting missing entities (MLM Encoding), or generating a compatibility score for ranking candidate triples (Separated Encoding).
* **How elements relate:** The top section defines the universal input representation. Sections (a), (b), and (c) are variations on a theme, showing different ways to mask, structure, and process that input to achieve different goals. The LLM is the central, reusable component in all three pipelines.
* **Notable patterns/anomalies:** A key pattern is the progressive decoupling of the triple components. Method (a) fully couples them, (b) decouples the tail via masking, and (c) fully decouples the tail from the head-relation pair. This progression likely involves a trade-off between computational cost, model capacity, and task specificity. The use of a separate `Score Function` in (c) is a notable architectural addition not present in the other two methods, indicating a need for a dedicated module to integrate separately encoded representations.
DECODING INTELLIGENCE...