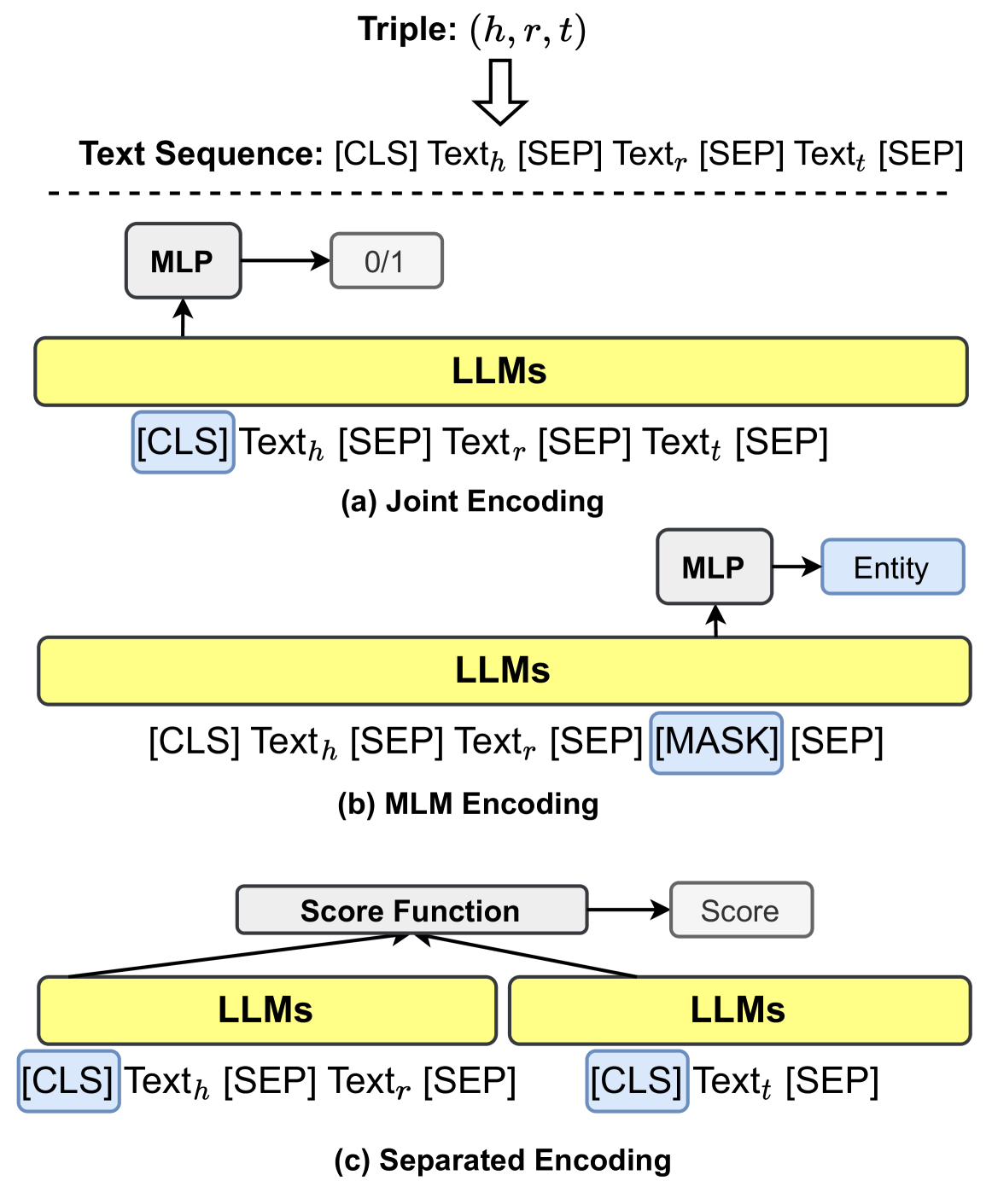
## Diagram: Text Encoding Methods for Triples in LLMs
### Overview
This diagram illustrates three distinct text encoding approaches for processing triples (h, r, t) in Large Language Models (LLMs). It shows how different tokenization strategies and model architectures handle the head entity (h), relation (r), and tail entity (t) components. The diagram emphasizes the use of special tokens ([CLS], [SEP], [MASK]) and demonstrates how these elements are processed through MLPs and score functions.
### Components/Axes
1. **Triple Representation**:
- (h, r, t) format shown at the top
- Text sequence format: [CLS] Text_h [SEP] Text_r [SEP] Text_t [SEP]
2. **Encoding Methods**:
- (a) Joint Encoding
- (b) MLM Encoding
- (c) Separated Encoding
3. **Key Components**:
- MLP (Multilayer Perceptron)
- Score Function
- Special Tokens: [CLS], [SEP], [MASK]
- Entity Representation
4. **Flow Direction**:
- Top-to-bottom processing flow
- Left-to-right token sequence processing
### Detailed Analysis
1. **Joint Encoding (a)**:
- All three text components (h, r, t) are jointly encoded
- Binary output (0/1) from MLP
- Full sequence: [CLS] Text_h [SEP] Text_r [SEP] Text_t [SEP]
2. **MLM Encoding (b)**:
- Relation text (Text_r) replaced with [MASK] token
- Entity representations preserved
- Output: Entity prediction from MLP
3. **Separated Encoding (c)**:
- Two-stage processing:
- First stage: [CLS] Text_h [SEP] Text_r [SEP]
- Second stage: [CLS] Text_t [SEP]
- Score function combines outputs from both stages
### Key Observations
1. All methods use [CLS] and [SEP] tokens for sequence boundary marking
2. MLM encoding introduces masked language modeling capabilities
3. Separated encoding enables modular processing of head/tail entities
4. Score function suggests fusion of multiple encoding perspectives
5. Binary classification (0/1) appears in joint encoding but not others
### Interpretation
This diagram reveals critical architectural choices in LLM-based triple processing:
1. **Joint Encoding** represents the simplest approach but may struggle with complex relations
2. **MLM Encoding** introduces relation prediction capabilities through masked modeling
3. **Separated Encoding** suggests a more sophisticated architecture that could better handle entity-relation interactions
4. The presence of a score function in separated encoding implies a more nuanced evaluation mechanism
5. The use of [MASK] in MLM encoding aligns with BERT-style pretraining objectives
The progression from joint to separated encoding demonstrates increasing complexity in handling semantic relationships, with each method offering different tradeoffs between computational efficiency and relational understanding. The diagram suggests that modern LLM architectures for knowledge graph tasks may benefit from hybrid approaches combining these encoding strategies.