# Technical Document Extraction: Perplexity vs. Context Size Chart
## 1. Component Isolation
* **Header/Legend Region:** Located in the top-right quadrant of the plot area.
* **Main Chart Area:** A line graph with a grid background, plotting Perplexity against Context Size.
* **Axes:** Y-axis (left) representing Perplexity; X-axis (bottom) representing Context size.
---
## 2. Metadata and Labels
* **Y-Axis Title:** Perplexity
* **X-Axis Title:** Context size
* **Y-Axis Markers:** 20, 40, 60, 80, 100
* **X-Axis Markers:** 0, 25000, 50000, 75000, 100000, 125000
* **Legend (Spatial Placement: Top-Right [x≈0.6, y≈0.8]):**
* **Blue Line:** `finetune on 32k(base=500)`
* **Red Line:** `Llama2-7B-Baseline`
---
## 3. Data Series Analysis and Trend Verification
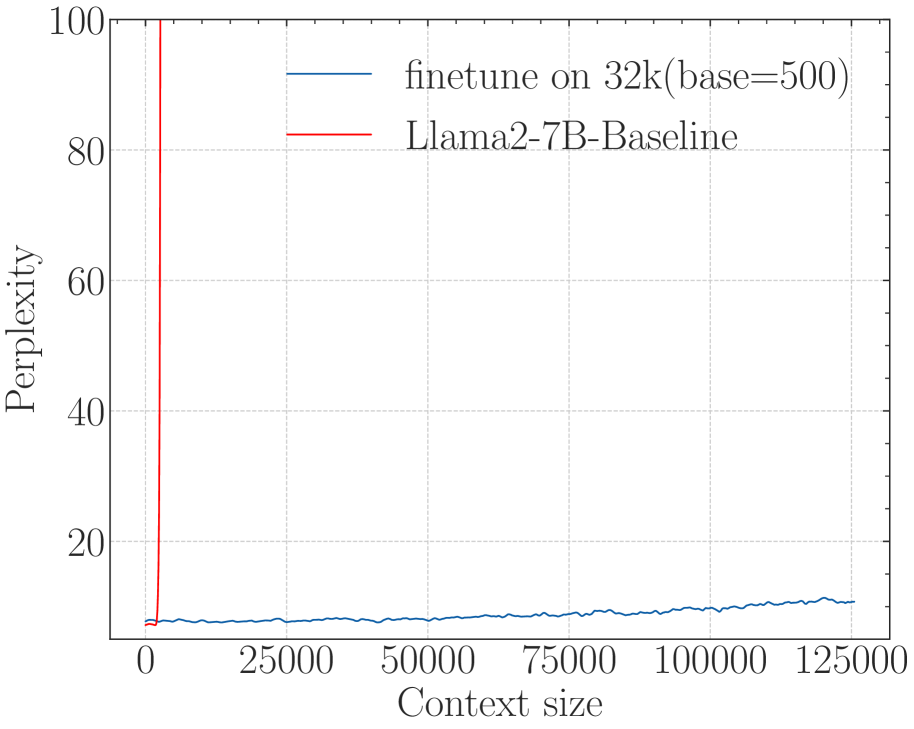
### Series 1: Llama2-7B-Baseline (Red Line)
* **Trend Description:** The line starts at a low perplexity (below 10) at a context size of 0. It remains stable for a very short duration and then exhibits a near-vertical upward spike, exiting the top of the chart (Perplexity > 100) before reaching a context size of approximately 4,000.
* **Key Data Points:**
* Context 0: Perplexity ≈ 8
* Context ~2,500: Perplexity begins sharp ascent.
* Context ~4,000: Perplexity > 100 (Off-chart).
### Series 2: finetune on 32k(base=500) (Blue Line)
* **Trend Description:** This line starts at a similar low perplexity (below 10) and maintains a very gradual, slightly oscillating upward slope across the entire horizontal range of the chart. It demonstrates extreme stability compared to the baseline.
* **Key Data Points:**
* Context 0: Perplexity ≈ 8
* Context 32,000: Perplexity ≈ 8-9
* Context 62,500: Perplexity ≈ 9
* Context 100,000: Perplexity ≈ 10
* Context 125,000: Perplexity ≈ 11
---
## 4. Comparative Summary
The chart illustrates the performance of two Large Language Models (LLMs) in terms of perplexity (where lower is better) as the input context window increases.
1. **Llama2-7B-Baseline:** This model fails rapidly as the context size exceeds its training window. Its perplexity explodes (goes to infinity/off-chart) almost immediately after the 2,000-4,000 token mark.
2. **finetune on 32k(base=500):** This model shows significant architectural or fine-tuning improvements. Despite being "finetuned on 32k," it maintains a low and stable perplexity (under 12) even when the context size is extended to 125,000 tokens, which is nearly 4x its stated fine-tuning length.
---
## 5. Grid and Scale Details
* **Grid:** Light gray dashed lines.
* **X-axis Major Ticks:** Every 25,000 units.
* **Y-axis Major Ticks:** Every 20 units.
* **Language:** English (No other languages detected).