## Horizontal Bar Chart: Model Performance Comparison
### Overview
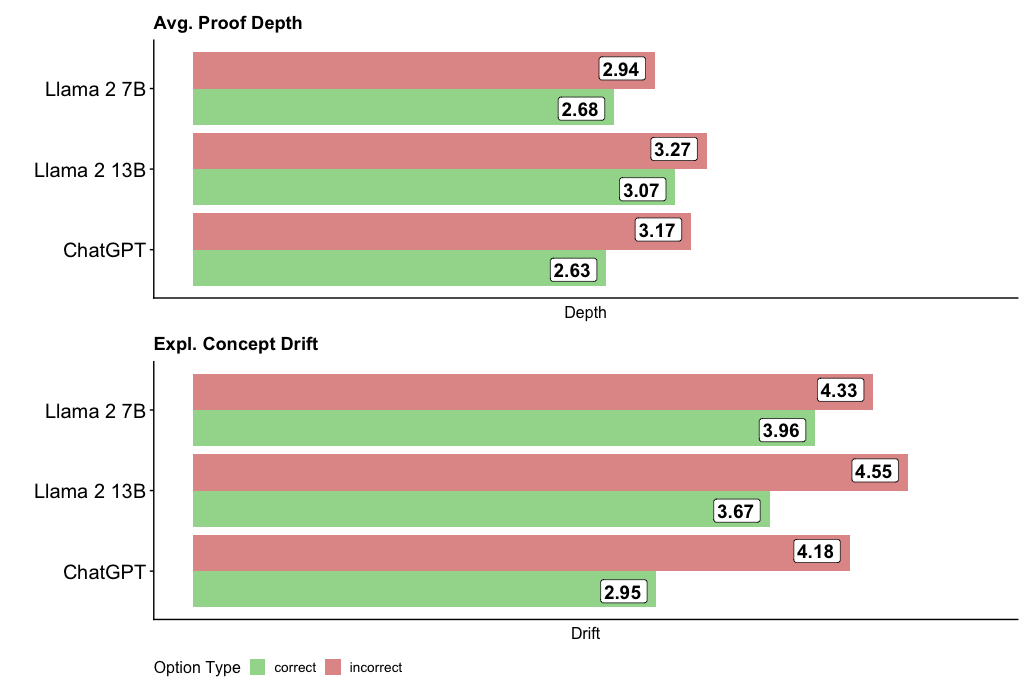
The image presents two horizontal bar charts comparing the performance of three language models (Llama 2 7B, Llama 2 13B, and ChatGPT) on two metrics: Average Proof Depth and Explanation Concept Drift. Each model has two bars representing "correct" and "incorrect" option types, indicated by green and red colors, respectively. The charts display the numerical values for each bar.
### Components/Axes
* **Chart Titles:**
* Top Chart: "Avg. Proof Depth"
* Bottom Chart: "Expl. Concept Drift"
* **Y-Axis Labels (Model Names):**
* Llama 2 7B
* Llama 2 13B
* ChatGPT
* **X-Axis Labels:**
* Top Chart: "Depth"
* Bottom Chart: "Drift"
* **Legend (Bottom):**
* "Option Type"
* Green: "correct"
* Red: "incorrect"
### Detailed Analysis
**Top Chart: Avg. Proof Depth**
* **Llama 2 7B:**
* Correct (Green): 2.68
* Incorrect (Red): 2.94
* **Llama 2 13B:**
* Correct (Green): 3.07
* Incorrect (Red): 3.27
* **ChatGPT:**
* Correct (Green): 2.63
* Incorrect (Red): 3.17
**Bottom Chart: Expl. Concept Drift**
* **Llama 2 7B:**
* Correct (Green): 3.96
* Incorrect (Red): 4.33
* **Llama 2 13B:**
* Correct (Green): 3.67
* Incorrect (Red): 4.55
* **ChatGPT:**
* Correct (Green): 2.95
* Incorrect (Red): 4.18
### Key Observations
* For both metrics, the "incorrect" option type consistently has a higher value than the "correct" option type for all models.
* Llama 2 13B has the highest "incorrect" value for "Avg. Proof Depth" (3.27).
* Llama 2 13B has the highest "incorrect" value for "Expl. Concept Drift" (4.55).
* ChatGPT has the lowest "correct" value for "Expl. Concept Drift" (2.95).
### Interpretation
The data suggests that all three models tend to have higher "Proof Depth" and "Concept Drift" when the option is incorrect. This could indicate that the models struggle more when generating incorrect answers, leading to more complex or convoluted reasoning processes. Llama 2 13B appears to have the highest "Concept Drift" when incorrect, potentially indicating a greater tendency to deviate from the correct explanation path. ChatGPT has the lowest "Concept Drift" when correct, suggesting it might be more consistent in its reasoning when providing correct answers. The difference between "correct" and "incorrect" values could be a useful metric for evaluating model reliability and identifying areas for improvement.