\n
## Bar Chart: Comparison of LLM Performance - Proof Depth & Concept Drift
### Overview
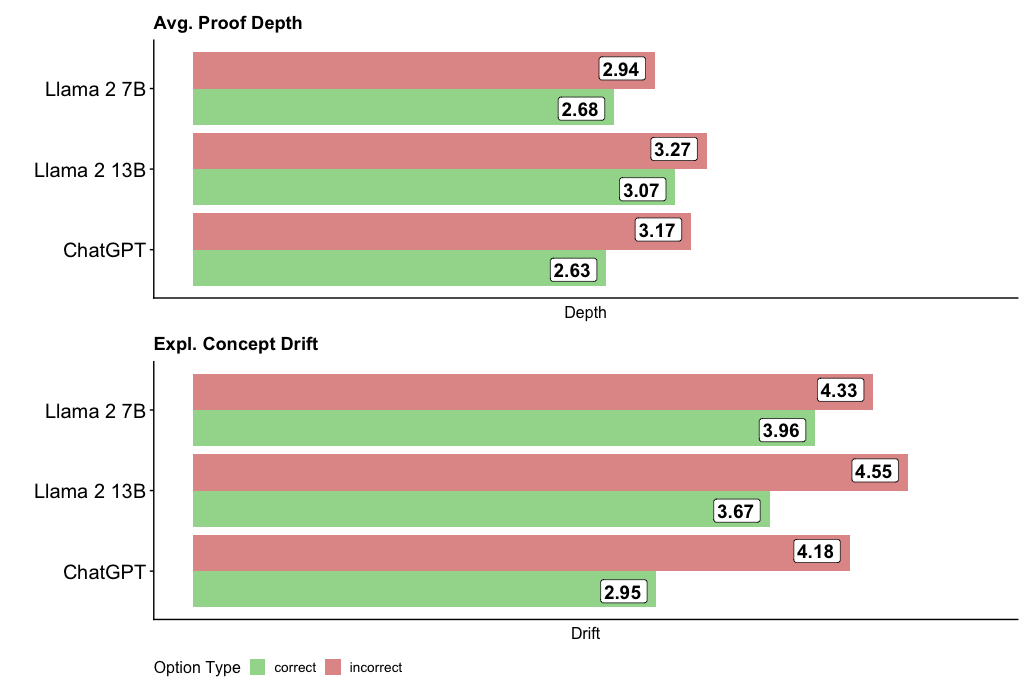
This image presents a comparative analysis of three Large Language Models (LLMs): Llama 2 7B, Llama 2 13B, and ChatGPT, across two metrics: Average Proof Depth and Explanatory Concept Drift. The performance is visualized using horizontal bar charts, with bars representing the average values for 'correct' and 'incorrect' option types.
### Components/Axes
* **Y-axis (Vertical):** Lists the three LLMs: Llama 2 7B, Llama 2 13B, and ChatGPT.
* **X-axis (Horizontal):** Represents the values for Depth and Drift. The scale is not explicitly labeled, but values range from approximately 2.6 to 4.5.
* **Title 1:** "Avg. Proof Depth" - positioned above the first bar chart.
* **Title 2:** "Expl. Concept Drift" - positioned above the second bar chart.
* **Legend (Bottom-Center):**
* Green: "correct"
* Red: "incorrect"
### Detailed Analysis or Content Details
**1. Average Proof Depth:**
* **Llama 2 7B:**
* Correct: Approximately 2.68
* Incorrect: Approximately 2.94
* **Llama 2 13B:**
* Correct: Approximately 3.07
* Incorrect: Approximately 3.27
* **ChatGPT:**
* Correct: Approximately 2.63
* Incorrect: Approximately 3.17
**2. Explanatory Concept Drift:**
* **Llama 2 7B:**
* Correct: Approximately 3.96
* Incorrect: Approximately 4.33
* **Llama 2 13B:**
* Correct: Approximately 3.67
* Incorrect: Approximately 4.55
* **ChatGPT:**
* Correct: Approximately 2.95
* Incorrect: Approximately 4.18
### Key Observations
* For both metrics, the 'incorrect' option type consistently exhibits higher values than the 'correct' option type across all LLMs.
* Llama 2 13B generally shows the highest values for both 'correct' and 'incorrect' options, suggesting a greater depth and drift compared to the other models.
* ChatGPT consistently has the lowest 'correct' values for both metrics.
* The difference between 'correct' and 'incorrect' values is more pronounced for Concept Drift than for Proof Depth.
### Interpretation
The data suggests that when LLMs produce incorrect responses, they tend to exhibit greater proof depth and concept drift compared to when they produce correct responses. This could indicate that incorrect answers are often more elaborately reasoned (leading to greater depth) but deviate further from the core concepts (leading to greater drift).
The higher values for Llama 2 13B might suggest that a larger model size allows for more complex reasoning, but also increases the potential for drifting away from the correct concepts. ChatGPT's lower 'correct' values could indicate a different approach to reasoning or a stronger focus on conciseness.
The consistent pattern of higher values for 'incorrect' responses across all models is a notable finding. It implies that identifying incorrect responses might be facilitated by analyzing the depth and drift of their reasoning processes. This could be valuable for developing methods to detect and mitigate errors in LLM outputs.