TECHNICAL ASSET FINGERPRINT
93ba1e9f2c858dced046b7e8
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
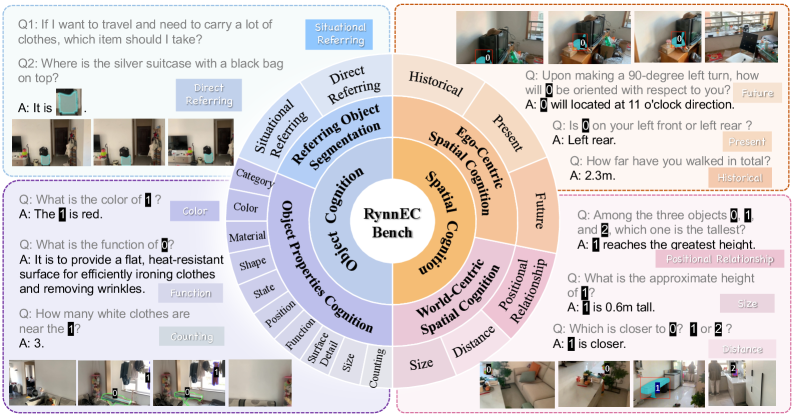
## Diagram: RynnEC Benchmark Conceptual Framework
### Overview
The image presents a conceptual diagram for "RynnEC Bench," a benchmark designed to evaluate embodied cognition capabilities. The diagram is structured as a multi-layered wheel or sunburst chart, with a central core and radiating segments that categorize different cognitive tasks. Surrounding the central diagram are four example panels, each containing question-and-answer (Q&A) pairs that illustrate specific task types within the benchmark's categories. The overall layout is informational and taxonomic, designed to show the scope and structure of the evaluation framework.
### Components/Axes
**Central Core:**
* **Label:** "RynnEC Bench" (center of the diagram).
**Primary Cognitive Categories (Inner Ring):**
1. **Object Cognition** (Left side, blue segment)
2. **Spatial Cognition** (Right side, orange segment)
**Sub-Categories (Middle Ring):**
* **Under Object Cognition:**
* Referring Object Segmentation
* Object Properties Cognition
* **Under Spatial Cognition:**
* EgoCentric Spatial Cognition
* World-Centric Spatial Cognition
**Task Types (Outer Ring):**
* **Under Referring Object Segmentation:**
* Direct Referring
* Situational Referring
* Category
* **Under Object Properties Cognition:**
* Color
* Material
* Shape
* State
* Position
* Function
* Spatial Relation
* Counting
* **Under EgoCentric Spatial Cognition:**
* Historical
* Present
* Future
* **Under World-Centric Spatial Cognition:**
* Positional Relationship
* Size
* Distance
**Example Panels (Surrounding the central diagram):**
* **Top-Left Panel (Direct/Situational Referring):** Contains two Q&A pairs with associated images.
* **Bottom-Left Panel (Object Properties Cognition):** Contains three Q&A pairs with associated images.
* **Top-Right Panel (EgoCentric Spatial Cognition):** Contains three Q&A pairs with associated images.
* **Bottom-Right Panel (World-Centric Spatial Cognition):** Contains three Q&A pairs with associated images.
### Detailed Analysis
**Example Panel Content (Transcribed Q&A):**
**Top-Left Panel (Direct/Situational Referring):**
* **Q1:** "If I want to travel and need to carry a lot of clothes, which item should I take?"
* **A:** "Situational Referring" (This is a label, not a direct answer).
* **Q2:** "Where is the silver suitcase with a black bag on top?"
* **A:** "It is" (The answer is cut off in the image).
* *Associated Images:* Show a room with luggage and bags.
**Bottom-Left Panel (Object Properties Cognition):**
* **Q1:** "What is the color of 1?"
* **A:** "The 1 is red." (The number '1' is a placeholder for a specific object in the image).
* **Q2:** "What is the function of 2?"
* **A:** "It is to provide a flat, heat-resistant surface for efficiently ironing clothes and removing wrinkles."
* **Q3:** "How many white clothes are near the 1?"
* **A:** "3."
* *Associated Images:* Show a room with an ironing board (labeled 2) and other objects.
**Top-Right Panel (EgoCentric Spatial Cognition):**
* **Q1:** "Upon making a 90-degree left turn, how will 3 be oriented with respect to you?"
* **A:** "3 will located at 11 o'clock direction."
* **Q2:** "Is 4 on your left front or left rear?"
* **A:** "Left rear."
* **Q3:** "How far have you walked in total?"
* **A:** "2.3m."
* *Associated Images:* Show a first-person perspective in a room with numbered objects.
**Bottom-Right Panel (World-Centric Spatial Cognition):**
* **Q1:** "Among the three objects 1, 3, and 2, which one is the tallest?"
* **A:** "1 reaches the greatest height."
* **Q2:** "What is the approximate height of 1?"
* **A:** "1 is 0.6m tall."
* **Q3:** "Which is closer to 1: 3 or 2?"
* **A:** "3 is closer."
* *Associated Images:* Show a room with numbered objects from a third-person perspective.
### Key Observations
1. **Hierarchical Structure:** The benchmark is organized hierarchically, moving from broad cognitive domains (Object, Spatial) to specific task types (Color, Distance, Future prediction).
2. **Multimodal Integration:** Every example Q&A is paired with a visual scene, indicating the benchmark requires understanding and reasoning about visual data.
3. **Task Diversity:** The tasks range from simple property identification ("What is the color?") to complex spatial reasoning ("Upon making a 90-degree left turn...") and functional understanding ("What is the function of...").
4. **Placeholder Notation:** The use of numbered placeholders (1, 2, 3, 4) in the questions refers to specific, annotated objects within the corresponding images, which are not fully legible in this overview diagram.
5. **Spatial Layout of Examples:** The example panels are positioned adjacent to their corresponding primary category segment (e.g., Object Properties examples are next to the blue "Object Cognition" segment).
### Interpretation
The RynnEC Bench diagram outlines a comprehensive evaluation framework for an AI's embodied cognition—its ability to understand and reason about objects and space within a visual environment, as if it were an agent interacting with that world.
* **What it demonstrates:** The benchmark is designed to test a wide spectrum of capabilities, from basic perception (identifying color, counting) to advanced reasoning (understanding object function, predicting egocentric spatial relationships after movement, comparing world-centric sizes and distances). The inclusion of "Historical," "Present," and "Future" under EgoCentric cognition suggests it also evaluates memory and predictive modeling based on an agent's own perspective and movement history.
* **Relationship between elements:** The central "RynnEC Bench" is the core concept, supported by the two pillars of Object and Spatial cognition. These pillars are broken down into increasingly granular and specific tasks, which are then illustrated with concrete, visual Q&A examples. This structure implies that performance on the specific, low-level tasks (outer ring) is used to measure competency in the broader cognitive domains (inner rings).
* **Notable design choices:** The separation of Spatial Cognition into "EgoCentric" (agent-relative) and "World-Centric" (absolute, scene-relative) is a critical distinction in robotics and embodied AI, highlighting the benchmark's focus on realistic agent-based reasoning. The "Situational Referring" task is particularly interesting, as it requires understanding context and intent (e.g., choosing luggage for a trip) rather than just visual attributes.
In essence, this diagram serves as a blueprint for a test suite that would challenge an AI to not just "see" a scene, but to *comprehend* it in a functional, spatial, and contextual manner relevant to physical interaction.
DECODING INTELLIGENCE...