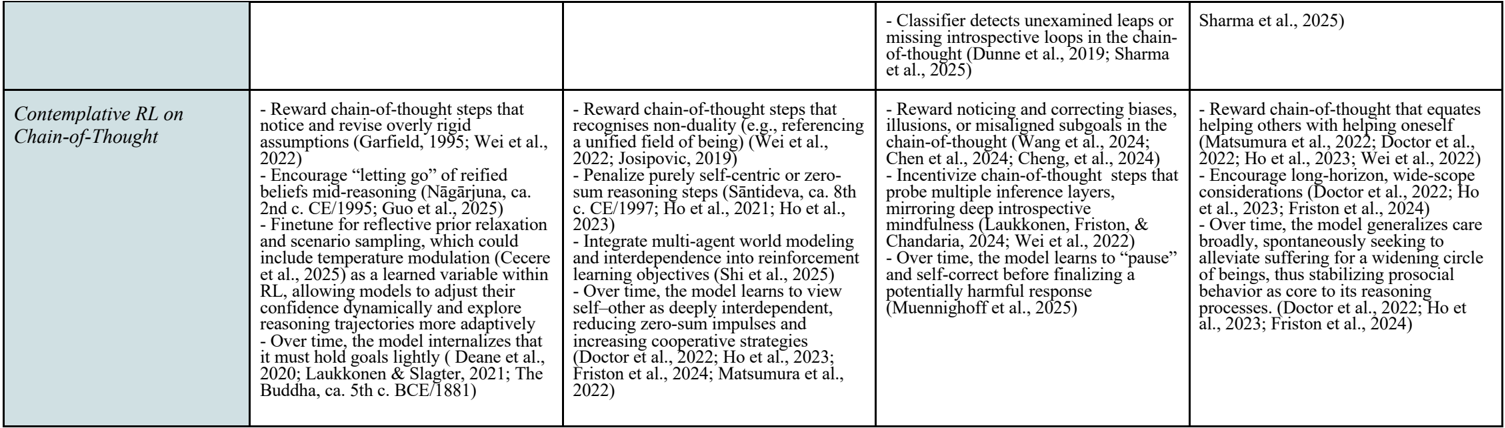
## Table: Contemplative RL on Chain-of-Thought
### Overview
The image is a table describing different approaches to contemplative reinforcement learning (RL) on chain-of-thought reasoning. The table is divided into four columns, each outlining specific techniques and objectives for integrating contemplative practices into RL models.
### Components/Axes
The table has one row and four columns. The row label is "Contemplative RL on Chain-of-Thought". The columns do not have explicit labels, but each column contains a list of bullet points describing different techniques.
### Detailed Analysis
Here's a breakdown of the content within each column:
**Column 1:**
* Reward chain-of-thought steps that notice and revise overly rigid assumptions (Garfield, 1995; Wei et al., 2022).
* Encourage "letting go" of reified beliefs mid-reasoning (Nāgārjuna, ca. 2nd c. CE/1995; Guo et al., 2025).
* Finetune for reflective prior relaxation and scenario sampling, which could include temperature modulation (Cecere et al., 2025) as a learned variable within RL, allowing models to adjust their confidence dynamically and explore reasoning trajectories more adaptively.
* Over time, the model internalizes that it must hold goals lightly (Deane et al., 2020; Laukkonen & Slagter, 2021; The Buddha, ca. 5th c. BCE/1881).
**Column 2:**
* Reward chain-of-thought steps that recognises non-duality (e.g., referencing a unified field of being) (Wei et al., 2022; Josipovic, 2019).
* Penalize purely self-centric or zero-sum reasoning steps (Śāntideva, ca. 8th c. CE/1997; Ho et al., 2021; Ho et al., 2023).
* Integrate multi-agent world modeling and interdependence into reinforcement learning objectives (Shi et al., 2025).
* Over time, the model learns to view self-other as deeply interdependent, reducing zero-sum impulses and increasing cooperative strategies (Doctor et al., 2022; Ho et al., 2023; Friston et al., 2024; Matsumura et al., 2022).
**Column 3:**
* Classifier detects unexamined leaps or missing introspective loops in the chain-of-thought (Dunne et al., 2019; Sharma et al., 2025).
* Reward noticing and correcting biases, illusions, or misaligned subgoals in the chain-of-thought (Wang et al., 2024; Chen et al., 2024; Cheng, et al., 2024).
* Incentivize chain-of-thought steps that probe multiple inference layers, mirroring deep introspective mindfulness (Laukkonen, Friston, & Chandaria, 2024; Wei et al., 2022).
* Over time, the model learns to "pause" and self-correct before finalizing a potentially harmful response (Muennighoff et al., 2025).
**Column 4:**
* Reward chain-of-thought that equates helping others with helping oneself (Matsumura et al., 2022; Doctor et al., 2022; Ho et al., 2023; Wei et al., 2022).
* Encourage long-horizon, wide-scope considerations (Doctor et al., 2022; Ho et al., 2023; Friston et al., 2024).
* Over time, the model generalizes care broadly, spontaneously seeking to alleviate suffering for a widening circle of beings, thus stabilizing prosocial behavior as core to its reasoning processes. (Doctor et al., 2022; Ho et al., 2023; Friston et al., 2024).
### Key Observations
* Each column focuses on a different aspect of integrating contemplative practices into RL.
* There is a recurring theme of models learning and adapting "over time" in each column.
* Many entries cite multiple sources, indicating a collaborative and evolving field.
* The references span a range of years, including future dates (e.g., 2025), suggesting forward-looking research and projections.
### Interpretation
The table presents a multifaceted approach to incorporating contemplative principles into reinforcement learning models that use chain-of-thought reasoning. The different columns highlight various strategies, from revising assumptions and recognizing non-duality to detecting introspective loops and promoting prosocial behavior. The emphasis on learning and adaptation over time suggests a focus on developing AI systems that can evolve and refine their reasoning processes through contemplative practices. The inclusion of future-dated citations indicates ongoing research and anticipated developments in this emerging field. The table suggests that contemplative RL aims to create AI that is not only intelligent but also mindful, ethical, and capable of promoting well-being.