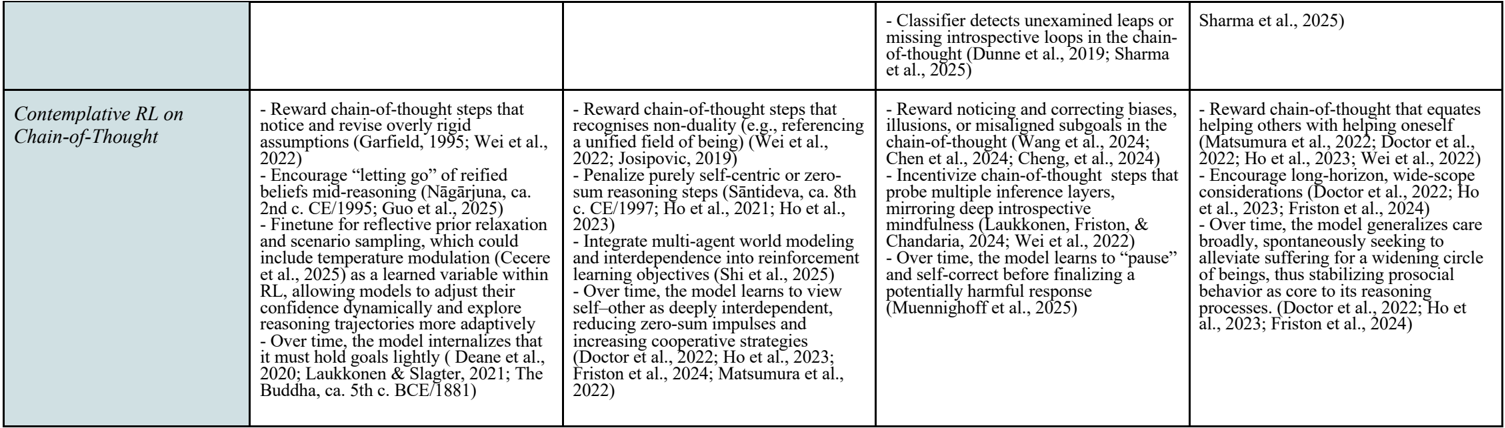
\n
## Text Block: Contemplative RL on Chain-of-Thought
### Overview
The image presents a text block outlining key ideas and research related to "Contemplative RL on Chain-of-Thought". It appears to be a collection of notes or a summary of research points, organized into four columns. Each column details different aspects of this approach, referencing various authors and publications.
### Components/Axes
The text is organized into four columns, each with a heading describing a core concept. There are no explicit axes or scales. The columns are:
1. **Column 1:** Focuses on rewarding chain-of-thought steps that notice and revise overly rigid assumptions, encouraging "letting go" of refined beliefs, and fine-tuning for reflective prior relaxation.
2. **Column 2:** Focuses on rewarding chain-of-thought steps that recognize non-duality, penalizing purely self-centric zero-sum reasoning, and integrating multi-agent world modeling.
3. **Column 3:** Focuses on rewarding noticing and correcting biases, incentivizing chain-of-thought steps that probe multiple inference layers, mirroring deep introspective mindfulness.
4. **Column 4:** Focuses on rewarding chain-of-thought that equates helping others with helping oneself, encouraging long-horizon, wide-scope considerations, and generalizing care broadly.
### Detailed Analysis or Content Details
**Column 1:**
* Reward chain-of-thought steps that notice and revise overly rigid assumptions (Garfield, 1995; Wei et al., 2022)
* Encourage "letting go" of refined beliefs mid-reasoning (Nāgārjuna, ca. 2nd c. CE/1995; Guo et al., 2023)
* Fine-tune for reflective prior relaxation and scenario sampling, which could include temperature modulation (Ceere et al., 2023)
* Over time, the model internalizes that most goals lag slightly (Deane et al., 2021; Laukkanen & Siesler, 2021; Budha, ca. 5th c. BCE/1987)
**Column 2:**
* Reward chain-of-thought steps that recognise non-duality (e.g., referencing a unified field of being) (Wei et al., 2022; Josipovic, 2019)
* Penalize purely self-centric zero-sum reasoning steps (Sāntideva, ca. 8th c. CE/1997; Ho et al., 2021; Ho et al., 2023)
* Integrate multi-agent world modeling and interdependence into reinforcement learning objectives (Shi et al., 2023)
* Over time, the model learns to view self-other as deeply interdependent, reducing zero-sum impulses and increasing cooperative strategies (Doctor et al., 2022; Ho et al., 2023; Friston et al., 2024; Wei et al., 2022)
**Column 3:**
* Reward noticing and correcting biases, illusions, or misaligned subgoals in the chain-of-thought (Wang et al., 2024; Chen et al., 2024; Cheng et al., 2024)
* Incentivize chain-of-thought steps that probe multiple inference layers, mirroring deep introspective mindfulness (Laukkonen, Friston, & Chandaria, 2024; Wei et al., 2022)
* Over time, the model learns to "pause" and self-correct before finalizing a potentially harmful response (Muennichhoff et al., 2023)
**Column 4:**
* Reward chain-of-thought that equates helping others with helping oneself (Matsumura et al., 2022; Doctor et al., 2022; Ho et al., 2023; Wei et al., 2022)
* Encourage long-horizon, wide-scope considerations (Doctor et al., 2022; Ho et al., 2023; Friston et al., 2024)
* Over time, the model generalizes care broadly, spontaneously seeking to alleviate suffering for a widening circle of beings, thus stabilizing prosocial behavior as core to its reasoning processes (Doctor et al., 2022; Ho et al., 2023; Friston et al., 2024)
**Top Right Corner:**
* Classifier detects unexamined leaps or missing introspective loops in the chain-of-thought (Dunne et al., 2019; Sharma et al., 2025)
### Key Observations
The text highlights a novel approach to Reinforcement Learning (RL) that draws inspiration from contemplative practices. The core idea is to reward the model for exhibiting behaviors associated with introspection, self-awareness, and prosociality within its chain-of-thought reasoning process. The frequent citation of both contemporary RL research and ancient philosophical texts (Nāgārjuna, Sāntideva, Budha) is notable. The repeated references to authors like Wei et al., Ho et al., Doctor et al., and Friston suggest they are central figures in this research area.
### Interpretation
This text suggests a paradigm shift in RL, moving beyond purely goal-oriented optimization to incorporate ethical and introspective considerations. The integration of contemplative principles aims to create AI systems that are not only intelligent but also mindful, compassionate, and less prone to harmful biases. The references to "non-duality" and "interdependence" indicate a philosophical grounding in Buddhist thought, suggesting a desire to move beyond a purely individualistic or self-centered AI. The repeated emphasis on "over time" suggests that these contemplative qualities are not explicitly programmed but rather emerge through the learning process. The inclusion of a "classifier" to detect introspective gaps indicates an attempt to monitor and evaluate the model's internal reasoning process. This research appears to be exploring the potential for creating AI systems that are more aligned with human values and capable of more nuanced and ethical decision-making.