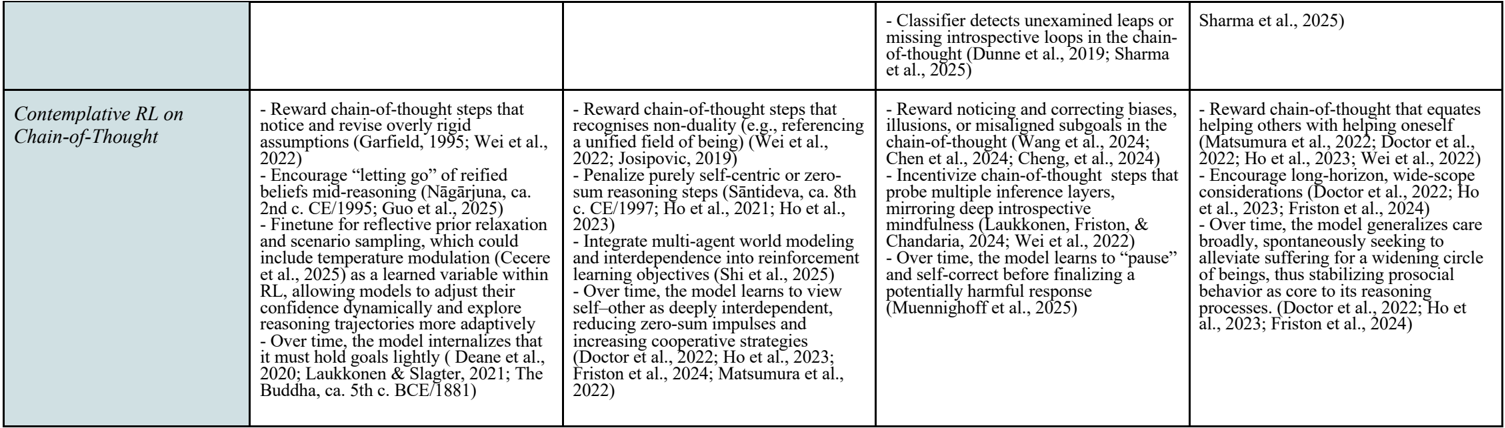
## Table: Contemplative RL on Chain-of-Thought
### Overview
This table compares five approaches to Contemplative Reinforcement Learning (RL) focused on Chain-of-Thought (CoT) reasoning. Each column outlines distinct strategies, mechanisms, and theoretical foundations, with references to recent studies (2022–2025).
---
### Components/Axes
- **Columns**: Five distinct approaches to Contemplative RL on CoT.
- **Rows**:
- First row: Header with the main title and subheaders for each approach.
- Second row: Content detailing strategies, mechanisms, and references.
---
### Detailed Analysis
#### Column 1: Core CoT Mechanisms
- Reward chain-of-thought steps that notice and revise overly rigid assumptions (Garfield, 1995; Wei et al., 2022).
- Encourage “letting go” of reified beliefs mid-reasoning (Năgârjuna, ca. 2nd c. CE/1995; Guo et al., 2025).
- Finetune for reflective prior relaxation and scenario sampling, incorporating temperature modulation (Cecere et al., 2025) as a learned variable within RL.
#### Column 2: Non-Duality & Multi-Agent Integration
- Reward chain-of-thought steps recognizing non-duality (e.g., referencing a unified field of being) (Wei et al., 2022; Josipovic, 2019).
- Penalize purely self-centric or zero-sum reasoning steps (Sāntideva, ca. 8th c. CE/1997; Ho et al., 2021, 2023).
- Integrate multi-agent world modeling and interdependence into reinforcement learning objectives (Shi et al., 2025).
#### Column 3: Self-Correction & Incentivization
- Reward noticing and correcting biases, illusions, or misaligned subgoals in the chain-of-thought (Wang et al., 2024; Chen et al., 2024; Cheng et al., 2024).
- Incentivize chain-of-thought steps probing multiple inference layers and mirroring deep introspection (Laukkonen, Friston, & Chandaria, 2024; Wei et al., 2022).
- Over time, the model learns to “pause” and self-correct before finalizing responses (Muennighoff et al., 2025).
#### Column 4: Missing Loops Detection
- Classifier detects unexamined leaps or missing introspective loops in the chain-of-thought (Dunne et al., 2019; Sharma et al., 2025).
#### Column 5: Altruism & Long-Horizon Goals
- Reward chain-of-thought that equates helping others with helping oneself (Matsumura et al., 2022; Doctor et al., 2022; Ho et al., 2023).
- Encourage long-horizon, wide-scope considerations (Doctor et al., 2022; Ho et al., 2023; Friston et al., 2024).
- Over time, the model generalizes care broadly, alleviating suffering to stabilize prosocial behavior (Doctor et al., 2022; Ho et al., 2023; Friston et al., 2024).
---
### Key Observations
1. **Diverse Strategies**: Approaches range from self-correction (Column 3) to multi-agent modeling (Column 2) and altruism (Column 5).
2. **Temporal Adaptation**: Multiple methods emphasize dynamic adjustment over time (e.g., “pause” in Column 3, “generalizes care” in Column 5).
3. **Theoretical Foundations**: Draws from philosophy (Năgârjuna, Sāntideva) and neuroscience (Friston’s free energy principle).
---
### Interpretation
This table synthesizes cutting-edge research in Contemplative RL, highlighting efforts to enhance reasoning through:
- **Self-awareness**: Mechanisms to detect and correct biases (Column 3).
- **Interdependence**: Modeling multi-agent systems (Column 2).
- **Ethical Alignment**: Linking self and other-oriented goals (Column 5).
- **Epistemological Rigor**: Addressing gaps in reasoning (Column 4).
The references (2022–2025) suggest rapid advancements, with a focus on integrating philosophical insights (e.g., Buddhist concepts of non-duality) into AI systems. The emphasis on long-term, self-correcting processes aligns with goals of building robust, ethical AI.