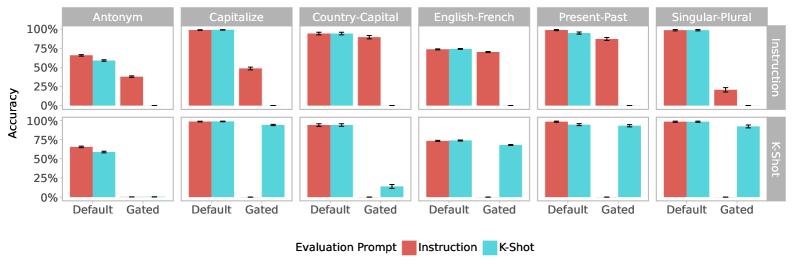
\n
## Grouped Bar Chart: Accuracy Comparison Across Tasks and Evaluation Methods
### Overview
The image displays a 2x6 grid of grouped bar charts comparing model accuracy across six different linguistic tasks. The comparison is made across two training methods (rows) and two evaluation prompt types (bar colors) for each task.
### Components/Axes
* **Chart Type:** Grouped Bar Chart (Small Multiples)
* **Y-Axis:** Labeled "Accuracy" on the far left. Scale runs from 0% to 100% in increments of 25%.
* **X-Axis (within each subplot):** Two categories: "Default" and "Gated".
* **Column Headers (Top):** Six task names: "Antonym", "Capitalize", "Country-Capital", "English-French", "Present-Past", "Singular-Plural".
* **Row Labels (Right Side):** Two training methods: "Instruction" (top row) and "K-Shot" (bottom row).
* **Legend (Bottom Center):** Titled "Evaluation Prompt". Contains two colored squares:
* Red square: "Instruction"
* Teal square: "K-Shot"
* **Data Series:** Each subplot contains four bars, grouped into two pairs (Default and Gated). Each pair contains a red bar (Instruction evaluation) and a teal bar (K-Shot evaluation).
### Detailed Analysis
**Data Extraction (Approximate Values):**
**Row 1: Instruction Training**
* **Antonym:**
* Default: Instruction (Red) ~65%, K-Shot (Teal) ~60%
* Gated: Instruction (Red) ~40%, K-Shot (Teal) ~0%
* **Capitalize:**
* Default: Instruction (Red) ~98%, K-Shot (Teal) ~98%
* Gated: Instruction (Red) ~50%, K-Shot (Teal) ~0%
* **Country-Capital:**
* Default: Instruction (Red) ~95%, K-Shot (Teal) ~95%
* Gated: Instruction (Red) ~90%, K-Shot (Teal) ~0%
* **English-French:**
* Default: Instruction (Red) ~75%, K-Shot (Teal) ~75%
* Gated: Instruction (Red) ~70%, K-Shot (Teal) ~0%
* **Present-Past:**
* Default: Instruction (Red) ~98%, K-Shot (Teal) ~95%
* Gated: Instruction (Red) ~85%, K-Shot (Teal) ~0%
* **Singular-Plural:**
* Default: Instruction (Red) ~98%, K-Shot (Teal) ~98%
* Gated: Instruction (Red) ~20%, K-Shot (Teal) ~0%
**Row 2: K-Shot Training**
* **Antonym:**
* Default: Instruction (Red) ~65%, K-Shot (Teal) ~60%
* Gated: Instruction (Red) ~0%, K-Shot (Teal) ~0%
* **Capitalize:**
* Default: Instruction (Red) ~98%, K-Shot (Teal) ~98%
* Gated: Instruction (Red) ~0%, K-Shot (Teal) ~95%
* **Country-Capital:**
* Default: Instruction (Red) ~95%, K-Shot (Teal) ~95%
* Gated: Instruction (Red) ~0%, K-Shot (Teal) ~15%
* **English-French:**
* Default: Instruction (Red) ~75%, K-Shot (Teal) ~75%
* Gated: Instruction (Red) ~0%, K-Shot (Teal) ~70%
* **Present-Past:**
* Default: Instruction (Red) ~98%, K-Shot (Teal) ~95%
* Gated: Instruction (Red) ~0%, K-Shot (Teal) ~95%
* **Singular-Plural:**
* Default: Instruction (Red) ~98%, K-Shot (Teal) ~98%
* Gated: Instruction (Red) ~0%, K-Shot (Teal) ~95%
### Key Observations
1. **Consistent High Performance on "Default":** For all six tasks, both training methods achieve high accuracy (mostly >60%, often >95%) when using the "Default" evaluation prompt, regardless of whether the evaluation prompt is "Instruction" (red) or "K-Shot" (teal).
2. **Catastrophic Drop with "Gated" Prompt:** The most striking pattern is the severe performance degradation when switching from the "Default" to the "Gated" evaluation prompt.
3. **Divergent Behavior by Training Method:**
* **Instruction Training (Top Row):** When using the "Gated" prompt, the "Instruction" evaluation (red bars) retains some accuracy (20-90% depending on task), while the "K-Shot" evaluation (teal bars) drops to near 0% for all tasks.
* **K-Shot Training (Bottom Row):** The pattern is inverted. With the "Gated" prompt, the "Instruction" evaluation (red bars) drops to 0% for all tasks, while the "K-Shot" evaluation (teal bars) retains significant accuracy for most tasks (15-95%).
4. **Task-Specific Vulnerability:** The "Capitalize" and "Singular-Plural" tasks show the most dramatic drops under the "Gated" condition for their non-preferred evaluation method (e.g., Instruction evaluation for K-Shot trained models).
### Interpretation
This chart demonstrates a critical failure mode related to **prompt sensitivity** and **training-evaluation alignment**.
* **What the data suggests:** The models are highly brittle. Their performance is not just a function of the task but is acutely dependent on the format of the evaluation prompt ("Default" vs. "Gated"). The "Gated" prompt appears to break the model's ability to follow instructions unless the evaluation method perfectly matches the training method.
* **Relationship between elements:** The training method ("Instruction" vs. "K-Shot") creates a strong bias. A model trained with one method becomes almost completely incapable of performing when evaluated with the *other* method under the "Gated" prompt condition. This indicates the models are not learning the underlying task robustly but are instead overfitting to the specific prompt format used during training.
* **Notable anomaly:** The near-perfect 0% scores are extreme outliers in typical model evaluation, signaling a complete breakdown rather than a gradual decline. This is a severe reliability issue for real-world deployment where input phrasing can vary.
* **Underlying implication:** The results argue strongly for more robust training paradigms that decouple task understanding from prompt formatting. It highlights a significant gap between achieving high benchmark scores (on "Default" prompts) and creating models that generalize reliably across different interaction styles.