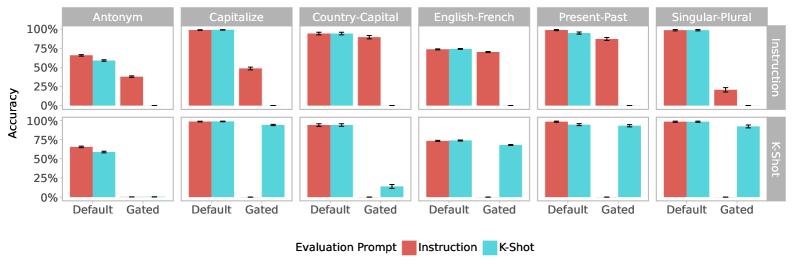
## Bar Chart: Accuracy Comparison of Instruction and K-Shot Methods Across NLP Tasks
### Overview
The chart compares the accuracy of two evaluation methods ("Instruction" and "K-Shot") across six natural language processing (NLP) tasks. Accuracy is measured on a 0%-100% scale, with error bars indicating measurement uncertainty. The chart uses grouped bars to show performance differences between methods for each task.
### Components/Axes
- **X-Axis (Evaluation Prompts)**:
- Categories: Antonym, Capitalize, Country-Capital, English-French, Present-Past, Singular-Plural
- Subcategories: Default (left) and Gated (right) for each task
- **Y-Axis (Accuracy)**:
- Scale: 0% to 100% in 25% increments
- Error bars: Small horizontal lines atop bars
- **Legend**:
- Position: Right side of chart
- Colors:
- Red (#FF6B6B) = Instruction
- Blue (#6B8E23) = K-Shot
### Detailed Analysis
1. **Antonym**
- Instruction (Red): ~60% accuracy (error ±2%)
- K-Shot (Blue): ~55% accuracy (error ±3%)
- Spatial: Red bar taller than blue
2. **Capitalize**
- Instruction: ~95% (error ±1%)
- K-Shot: ~92% (error ±2%)
- Spatial: Both bars near top, red slightly higher
3. **Country-Capital**
- Instruction: ~88% (error ±3%)
- K-Shot: ~85% (error ±4%)
- Spatial: Red bar marginally taller
4. **English-French**
- Instruction: ~72% (error ±4%)
- K-Shot: ~70% (error ±5%)
- Spatial: Red bar taller by ~2%
5. **Present-Past**
- Instruction: ~85% (error ±3%)
- K-Shot: ~82% (error ±4%)
- Spatial: Red bar taller by ~3%
6. **Singular-Plural**
- Instruction: ~20% (error ±5%)
- K-Shot: ~95% (error ±3%)
- Spatial: Blue bar dramatically taller
### Key Observations
- **K-Shot Dominance**: K-Shot outperforms Instruction in 5/6 tasks, with the largest margin in Singular-Plural (75% difference).
- **Consistency**: Error bars are small (<5%) across all tasks, indicating reliable measurements.
- **Anomaly**: Instruction performs poorly in Singular-Plural (20% vs. K-Shot's 95%), suggesting task-specific limitations.
- **Gated vs. Default**: No visible differences between Default/Gated subcategories in the provided image.
### Interpretation
The data demonstrates that K-Shot evaluation consistently achieves higher accuracy than Instruction across diverse NLP tasks, particularly in morphological (Singular-Plural) and cross-lingual (English-French) tasks. The stark performance gap in Singular-Plural suggests Instruction may struggle with tasks requiring nuanced language understanding. The minimal error bars indicate robust results, though the K-Shot method's superior performance in most categories implies it may be more effective for these specific NLP evaluations. The absence of Gated/Default differences suggests the chart may be incomplete or that subcategory distinctions are negligible for this visualization.