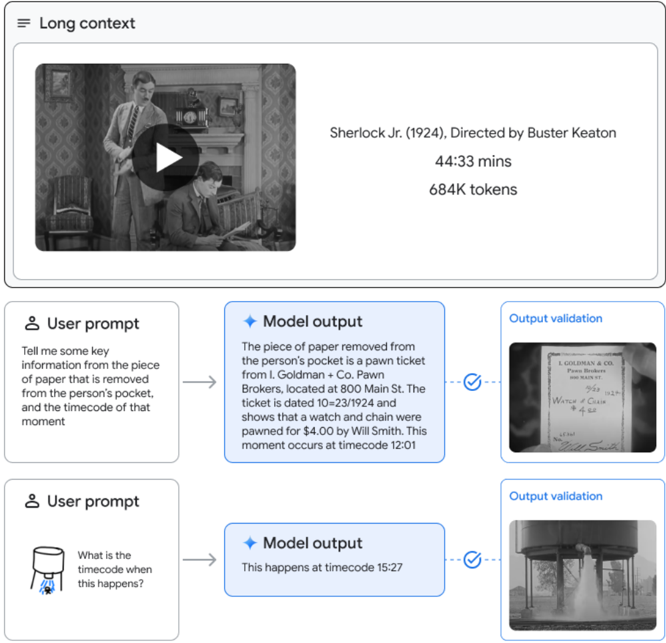
## Diagram: Multimodal AI Long-Context Video Analysis Process
### Overview
The image is a technical flowchart illustrating the process and capabilities of a multimodal AI system designed for detailed analysis of long-form video content. It demonstrates how the system processes a full-length film, responds to specific user queries about visual and textual details within the video, and validates its outputs against the source material.
### Components/Axes
The diagram is organized into three main horizontal sections:
1. **Top Section (Long Context Input):**
* **Header Label:** "Long context" (top-left).
* **Video Player Interface:** Contains a black-and-white thumbnail from the film "Sherlock Jr." showing two men in an office setting. A large play button icon is overlaid in the center.
* **Metadata Text (to the right of the thumbnail):**
* "Sherlock Jr. (1924), Directed by Buster Keaton"
* "44:33 mins"
* "684K tokens"
2. **Middle Section (First Query-Response-Validation Cycle):**
* **User Prompt Box (left):** Contains a user icon and the text: "Tell me some key information from the piece of paper that is removed from the person's pocket, and the timecode of that moment".
* **Arrow:** Points from the User Prompt to the Model Output.
* **Model Output Box (center):** Contains a sparkle icon and the text: "The piece of paper removed from the person's pocket is a pawn ticket from I. Goldman + Co. Pawn Brokers, located at 800 Main St. The ticket is dated 10/23/1924 and shows that a watch and chain were pawned for $4.00 by Wm. Smith. This moment occurs at timecode 12:01".
* **Arrow:** Points from the Model Output to the Output Validation.
* **Output Validation Box (right):** Contains the label "Output validation" and a checkmark icon. Below is a cropped, close-up image of the actual pawn ticket from the film, showing handwritten text that matches the model's description.
3. **Bottom Section (Second Query-Response-Validation Cycle):**
* **User Prompt Box (left):** Contains a user icon and a small image of a water tower with water spraying from its base. The text asks: "What is the timecode when this happens?".
* **Arrow:** Points from the User Prompt to the Model Output.
* **Model Output Box (center):** Contains a sparkle icon and the text: "This happens at timecode 15:27".
* **Arrow:** Points from the Model Output to the Output Validation.
* **Output Validation Box (right):** Contains the label "Output validation" and a checkmark icon. Below is a cropped frame from the film showing the water tower with water actively spraying, corresponding to the described event.
### Detailed Analysis
* **Process Flow:** The diagram depicts a linear, three-step process for each query: 1) User poses a question (text or image-based) about the video content, 2) The AI model generates a detailed textual answer, and 3) The system validates the answer by retrieving and displaying the exact frame or visual evidence from the video that supports the response.
* **Data Extraction:** The model successfully extracts both textual information (reading the pawn ticket: "I. Goldman + Co.", "800 Main St.", "10/23/1924", "watch and chain", "$4.00", "Wm. Smith") and visual event information (identifying the moment water sprays from the tower).
* **Temporal Grounding:** A key function highlighted is precise timecode localization. The model provides specific timestamps ("12:01" and "15:27") for queried events within the 44-minute, 33-second film.
* **Tokenization Context:** The "684K tokens" metric indicates the system processes the entire video as a massive sequence of data tokens, enabling long-context understanding.
### Key Observations
* **Validation is Integral:** The "Output validation" step is a critical component, showing a direct visual correlation between the model's text output and the source video frame. This serves as a proof of accuracy.
* **Multimodal Input:** The system accepts both text-based queries ("Tell me some key information...") and image-based queries (the picture of the water tower).
* **High Specificity:** The model's outputs are highly specific, providing exact names, dates, monetary values, addresses, and timecodes rather than general descriptions.
* **Film as Data Source:** The entire film "Sherlock Jr." is treated as a structured dataset from which precise information can be queried and retrieved.
### Interpretation
This diagram demonstrates a sophisticated multimodal AI system capable of deep, forensic-level analysis of long-form video. It moves beyond simple captioning to perform complex information retrieval tasks that require:
1. **Visual Text Recognition (OCR):** Reading and understanding handwritten text within a scene.
2. **Event Detection & Temporal Localization:** Identifying a specific visual event (water spraying) and pinpointing its exact location in a timeline.
3. **Long-Context Reasoning:** Maintaining coherence and accuracy across a 44-minute video represented by 684,000 tokens.
4. **Grounded Validation:** Providing evidence for its claims by linking outputs directly to source frames, which is crucial for trust and verification in applications like archival research, film analysis, or legal video review.
The process implies the AI has a unified, indexed understanding of the video's visual, textual, and temporal dimensions, allowing it to act as an expert analyst who can instantly locate and explain any detail upon request. The inclusion of validation frames underscores a design principle focused on accuracy and explainability.