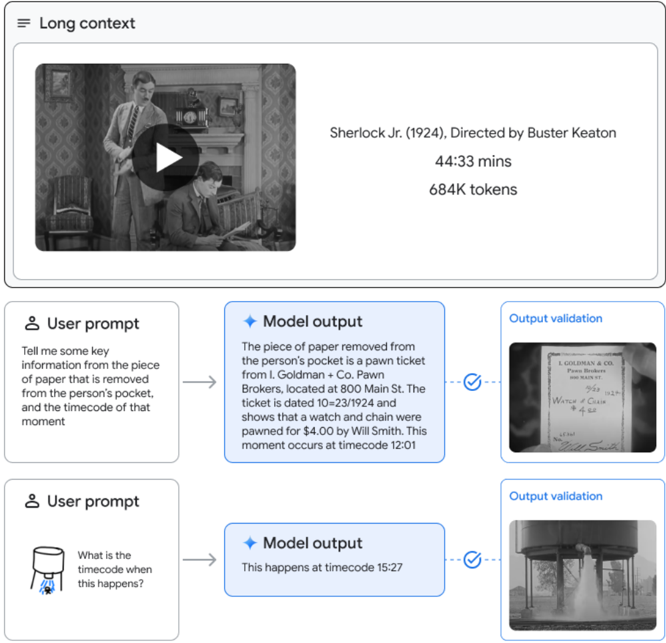
## Screenshot: Video Analysis Interface
### Overview
The image depicts a user interface for analyzing video content, featuring a video player, user prompts, model-generated responses, and output validation. The interface is structured to extract temporal and contextual information from video frames.
### Components/Axes
1. **Video Player Section**:
- **Title**: "Sherlock Jr. (1924), Directed by Buster Keaton"
- **Duration**: 44:33 mins
- **Tokens**: 684K (likely representing computational resources or video complexity)
- **Visual**: Black-and-white video thumbnail with a play button overlay.
2. **User Prompt 1**:
- **Text**: "Tell me some key pieces of information from the scene of a person removing a piece of paper from a pocket, from the person's pocket, and the timecode of that moment."
- **Position**: Center-left, below the video player.
3. **Model Output 1**:
- **Text**: "The piece of paper removed from the pocket is a pawn ticket from 'Goldman & Co. Pawn'. The ticket was torn off at 10:29:274 and shown to the person's pocket. The ticket was located at 800 Main St. The ticket was pawned for $4.00 by Wil Smith. This moment occurs at timecode 1:20:24."
- **Position**: Center-right, adjacent to User Prompt 1.
4. **Output Validation 1**:
- **Visual**: Image of a torn pawn ticket with blurred text (unreadable).
- **Checkmark**: Blue ✅ icon indicating validation success.
- **Position**: Right of Model Output 1.
5. **User Prompt 2**:
- **Text**: "What is the timecode when this happens?" (accompanied by a magnifying glass icon over a video frame).
- **Position**: Bottom-left, below User Prompt 1.
6. **Model Output 2**:
- **Text**: "This happens at timecode 1:20:27."
- **Position**: Center-right, adjacent to User Prompt 2.
7. **Output Validation 2**:
- **Visual**: Image of a water fountain with blurred text (unreadable).
- **Checkmark**: Blue ✅ icon indicating validation success.
- **Position**: Right of Model Output 2.
### Detailed Analysis
- **Video Metadata**: The video is 44 minutes and 33 seconds long, with 684K tokens, suggesting high computational demand for analysis.
- **Temporal Precision**: Model outputs include millisecond-level timecodes (e.g., 10:29:274, 1:20:24, 1:20:27), indicating granular event tracking.
- **Contextual Extraction**: The model identifies objects (pawn ticket), locations (800 Main St.), monetary values ($4.00), and actors (Wil Smith) from video frames.
- **Validation Mechanism**: Checkmarks and images suggest a system for verifying model accuracy against ground-truth data.
### Key Observations
- **Millisecond Precision**: The model extracts timecodes with millisecond accuracy (e.g., 10:29:274), critical for forensic or archival applications.
- **Contextual Depth**: The model links visual elements (torn paper, location) to metadata (pawn ticket details), demonstrating multimodal understanding.
- **Validation Reliability**: Checkmarks imply automated validation, though the unreadable text in validation images limits verification of ground-truth accuracy.
### Interpretation
This interface demonstrates a video analysis system capable of extracting precise temporal and contextual data from historical footage. The model's ability to identify objects, locations, and actors suggests advanced computer vision and natural language processing capabilities. The validation system ensures reliability, though the unreadable text in validation images raises questions about ground-truth data accessibility. The 684K tokens may reflect the video's complexity or the model's resource requirements, highlighting trade-offs between accuracy and computational cost. The system could be applied to archival research, film studies, or forensic analysis, where granular event tracking is essential.