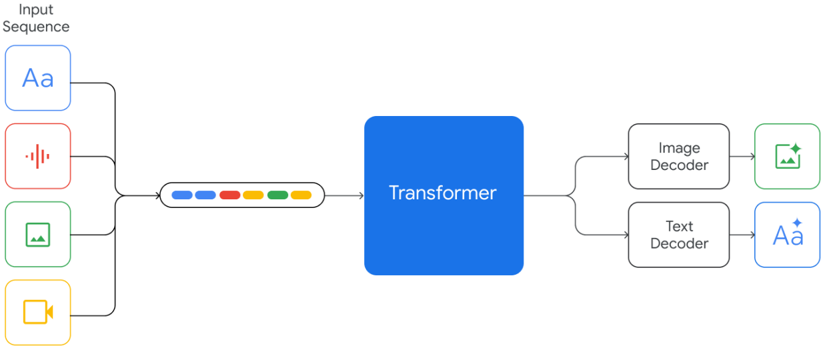
## Diagram: Transformer Model
### Overview
The image is a diagram illustrating a transformer model that takes an input sequence of various data types (text, audio, image, video) and outputs either an image or text. The diagram shows the flow of data from the input sequence through a transformer and then to either an image decoder or a text decoder.
### Components/Axes
* **Input Sequence:** This is the starting point of the diagram, representing the input to the model. It consists of four data types:
* Text (represented by "Aa" in a blue box)
* Audio (represented by a red sound wave icon in a red box)
* Image (represented by a green image icon in a green box)
* Video (represented by a yellow video camera icon in a yellow box)
* **Transformer:** A blue rectangle labeled "Transformer" represents the core of the model.
* **Image Decoder:** A rounded rectangle labeled "Image Decoder" processes the output from the transformer to generate an image.
* **Text Decoder:** A rounded rectangle labeled "Text Decoder" processes the output from the transformer to generate text.
* **Outputs:**
* Image (represented by a green image icon in a green box)
* Text (represented by "Aa" in a blue box)
* **Connecting Lines:** Black lines with arrowheads indicate the flow of data between the components.
* **Intermediate Representation:** A rounded rectangle containing a sequence of colored blocks (blue, red, yellow, green, yellow) represents an intermediate representation of the input sequence after processing.
### Detailed Analysis or ### Content Details
1. **Input Sequence:** The input sequence consists of four different data types.
2. **Intermediate Representation:** The input sequence is converted into an intermediate representation consisting of a sequence of colored blocks. The order of the colors is blue, red, yellow, green, yellow.
3. **Transformer:** The transformer processes the intermediate representation.
4. **Decoders:** The output of the transformer is fed into either an image decoder or a text decoder.
5. **Outputs:** The image decoder outputs an image, and the text decoder outputs text.
### Key Observations
* The diagram shows a multi-modal transformer model that can handle different types of input data.
* The model can output either an image or text, depending on the decoder used.
* The intermediate representation is a key component of the model, allowing the transformer to process different types of data in a unified way.
### Interpretation
The diagram illustrates a transformer model capable of processing various input data types (text, audio, image, video) and generating either an image or text as output. The model uses an intermediate representation to unify the different input types before processing them with the transformer. This suggests a flexible architecture that can be adapted to different tasks and data modalities. The model's ability to output both images and text indicates its potential for applications such as image captioning, text-to-image generation, and multi-modal translation.