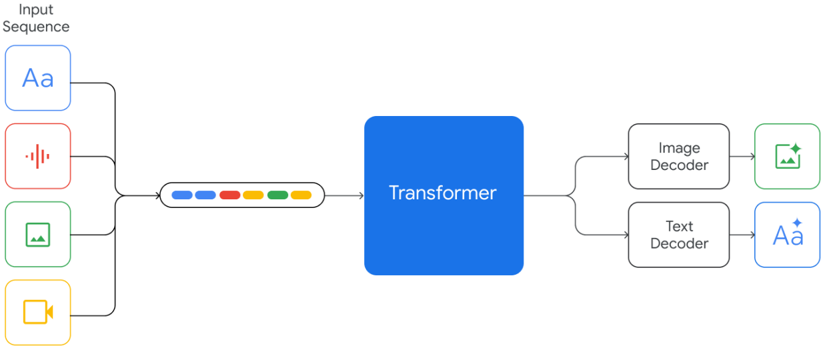
## Diagram: Multimodal Transformer Architecture
### Overview
The image is a technical block diagram illustrating the architecture of a multimodal AI system. It depicts how various input data types (text, audio, image, video) are processed through a central Transformer model and then decoded into specific output modalities (image and text). The flow is from left to right.
### Components/Axes
The diagram is organized into three main sections from left to right:
1. **Input Sequence (Left Column):**
* A vertical stack of four rounded square icons, each representing a different input modality.
* **Top Icon (Blue):** Contains the text "Aa". Represents **Text** input.
* **Second Icon (Red):** Contains a vertical waveform symbol. Represents **Audio** input.
* **Third Icon (Green):** Contains a simple landscape picture icon. Represents **Image** input.
* **Bottom Icon (Yellow):** Contains a video camera icon. Represents **Video** input.
* All four icons are connected by lines that converge into a single path.
2. **Processing Core (Center):**
* **Input Sequence Representation:** A horizontal, pill-shaped container holding six colored squares (blue, blue, red, yellow, green, orange). This represents the combined, tokenized sequence of the multimodal inputs.
* **Transformer Block:** A large, solid blue rectangle labeled "Transformer" in white text. This is the central processing unit of the architecture. An arrow points from the input sequence representation into this block.
3. **Output Decoders (Right Column):**
* The output from the Transformer splits into two paths.
* **Top Path:** Leads to a rounded rectangle labeled "Image Decoder". An arrow from this decoder points to a green rounded square icon containing a picture icon with a sparkle, representing a generated or processed **Image** output.
* **Bottom Path:** Leads to a rounded rectangle labeled "Text Decoder". An arrow from this decoder points to a blue rounded square icon containing the text "Aa" with a sparkle, representing generated or processed **Text** output.
### Detailed Analysis
* **Data Flow:** The diagram establishes a clear, unidirectional data flow: `Input Modalities -> Combined Sequence -> Transformer -> Modality-Specific Decoders -> Output`.
* **Multimodal Integration:** The system is designed to accept and process at least four distinct data types (text, audio, image, video) simultaneously or in sequence, as indicated by the "Input Sequence" label and the combined token representation.
* **Central Processing:** All input modalities are fused and processed by a single, unified "Transformer" model, suggesting an architecture where cross-modal understanding and generation occur within this core component.
* **Specialized Outputs:** The system has dedicated decoder pathways for generating outputs in specific modalities (image and text), implying the Transformer's internal representations are suitable for multiple downstream tasks.
### Key Observations
* **Color Coding:** Colors are used consistently to associate modalities: Blue for text, Red for audio, Green for image, and Yellow for video. This coding is maintained from the input icons to the combined sequence tokens and the final output icons.
* **Symmetry and Asymmetry:** The input side is symmetric with four modalities, while the output side is asymmetric with only two decoder types shown. This may indicate the system's primary capabilities or the specific focus of this architectural diagram.
* **Abstraction Level:** The diagram is a high-level architectural overview. It abstracts away details like model size, specific tokenization methods, training procedures, and the internal mechanisms of the Transformer or decoders.
### Interpretation
This diagram represents a **unified multimodal foundation model architecture**. The core principle is the use of a single Transformer to process and understand information from diverse sensory inputs (text, sight, sound). The "Input Sequence" with mixed-color tokens suggests that data from all modalities is converted into a common format (likely embeddings or tokens) and interleaved before being fed into the model.
The architecture implies several key capabilities:
1. **Multimodal Understanding:** The model can jointly reason about text, images, audio, and video within a single context window.
2. **Cross-Modal Generation:** By having separate decoders, the model can generate outputs in one modality based on inputs from others (e.g., generating a text description from an image and audio clip, or generating an image from a text prompt).
3. **Scalability and Generalization:** The design follows the trend of large, general-purpose models that can be adapted to various tasks through fine-tuning or prompting, rather than having separate, specialized models for each input-output pair.
The absence of specific details (like "Vision Transformer" or "Wav2Vec") indicates this is a conceptual schematic meant to communicate the overall system design and data flow, not a detailed engineering blueprint. It highlights the trend towards building AI systems that can perceive and interact with the world through multiple channels, much like humans do.