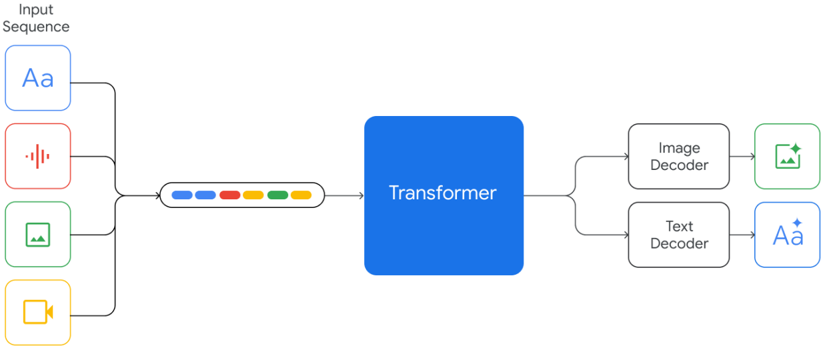
## Transformer Architecture
### Overview
The image depicts a schematic diagram of a Transformer architecture, which is a type of neural network used for natural language processing (NLP) tasks. The diagram shows the flow of input data through various components of the Transformer model.
### Components/Axes
- **Input Sequence**: Represented by a series of icons, including a text icon (Aa), a sound icon (with vertical lines), an image icon (with a picture of a mountain), and a video icon (with a camera).
- **Transformer**: A central blue box labeled "Transformer" that processes the input sequence.
- **Image Decoder**: A component that processes the image input.
- **Text Decoder**: A component that processes the text input.
- **Decoder**: A component that processes the output sequence.
### Detailed Analysis or ### Content Details
The input sequence is processed by the Transformer, which then outputs a sequence of tokens. The output sequence is processed by the Image Decoder and the Text Decoder, which generate the final output.
### Key Observations
The Transformer architecture is designed to handle sequential data, such as text and images, by using self-attention mechanisms. The self-attention mechanism allows the model to weigh the importance of different parts of the input sequence when generating the output sequence.
### Interpretation
The Transformer architecture is a powerful tool for NLP tasks, such as language translation, text summarization, and question answering. It has been shown to outperform traditional recurrent neural network (RNN) models in many tasks. The architecture is based on the concept of self-attention, which allows the model to focus on different parts of the input sequence when generating the output sequence. This makes the Transformer architecture well-suited for tasks that require understanding the context of the input sequence.