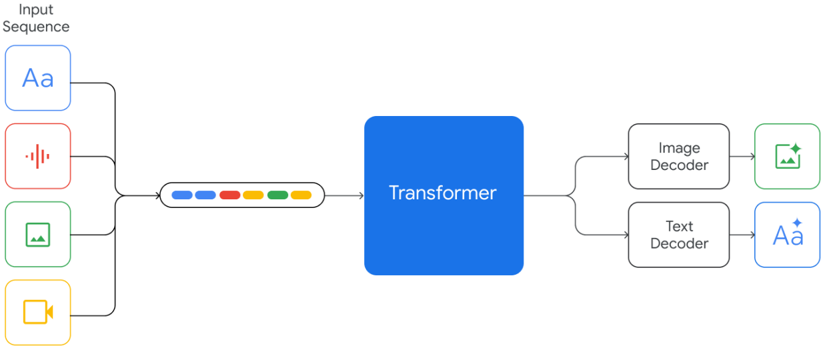
## Diagram: Multimodal Transformer System Architecture
### Overview
The diagram illustrates a multimodal transformer system that processes diverse input sequences (text, audio, image, video) through a central transformer component, producing specialized outputs via image and text decoders. The architecture emphasizes bidirectional data flow and modality-specific processing.
### Components/Axes
1. **Input Sequence Block**:
- Contains four modality-specific inputs:
- **Text**: "Aa" (blue box)
- **Audio**: Waveform icon (red box)
- **Image**: Mountain icon (green box)
- **Video**: Camera icon (yellow box)
- Positioned at top-left, connected via black lines to the transformer.
2. **Transformer Core**:
- Central blue box labeled "Transformer"
- Receives aggregated input from all modalities
- Outputs split into two decoder pathways
3. **Output Decoders**:
- **Image Decoder** (green box):
- Receives transformed data from the transformer
- Outputs a green image icon with a star (✨)
- **Text Decoder** (black box):
- Receives transformed data from the transformer
- Outputs "Aa" with a star (✨)
4. **Legend/Color Coding**:
- Blue: Text modality
- Red: Audio modality
- Green: Image modality
- Yellow: Video modality
- Star symbols (✨) denote enhanced output states
### Spatial Grounding
- **Top-Left**: Input sequence components arranged vertically
- **Center**: Transformer as the processing hub
- **Right-Side**: Decoders positioned horizontally
- **Color Consistency**: Input modality colors match their respective decoder outputs
### Detailed Analysis
1. **Input Processing**:
- All four modalities (text, audio, image, video) feed into the transformer simultaneously
- Black connecting lines suggest sequential processing steps
2. **Transformer Function**:
- Acts as a fusion layer for multimodal data
- Outputs split into specialized decoder pathways
3. **Decoder Specialization**:
- Image decoder produces visual outputs (green icon)
- Text decoder generates textual outputs (blue "Aa")
4. **Star Symbolism**:
- ✨ appears on both output types, suggesting:
- Quality enhancement
- Special processing flag
- Priority indicator
### Key Observations
1. **Modality Agnostic Input**:
- System accepts multiple input types without preference
- All modalities contribute equally to transformer input
2. **Bidirectional Output**:
- Single input sequence generates both text and image outputs
- Implies cross-modal translation capability
3. **Star Annotation**:
- Consistent use across outputs suggests systematic importance
- May indicate confidence scores or special processing
### Interpretation
This architecture demonstrates a unified approach to multimodal processing where:
1. **Transformer Fusion**: The central component integrates diverse data types before specialization
2. **Decoder Specialization**: Separate pathways maintain modality-specific characteristics
3. **Enhanced Outputs**: Star symbols likely represent system confidence or processing priority
The design suggests applications in:
- Cross-modal search systems
- Multimodal content generation
- Unified AI assistants handling text, audio, and visual inputs
Notable absence of explicit temporal processing components (e.g., time stamps) suggests this represents a static processing snapshot rather than real-time streaming architecture.