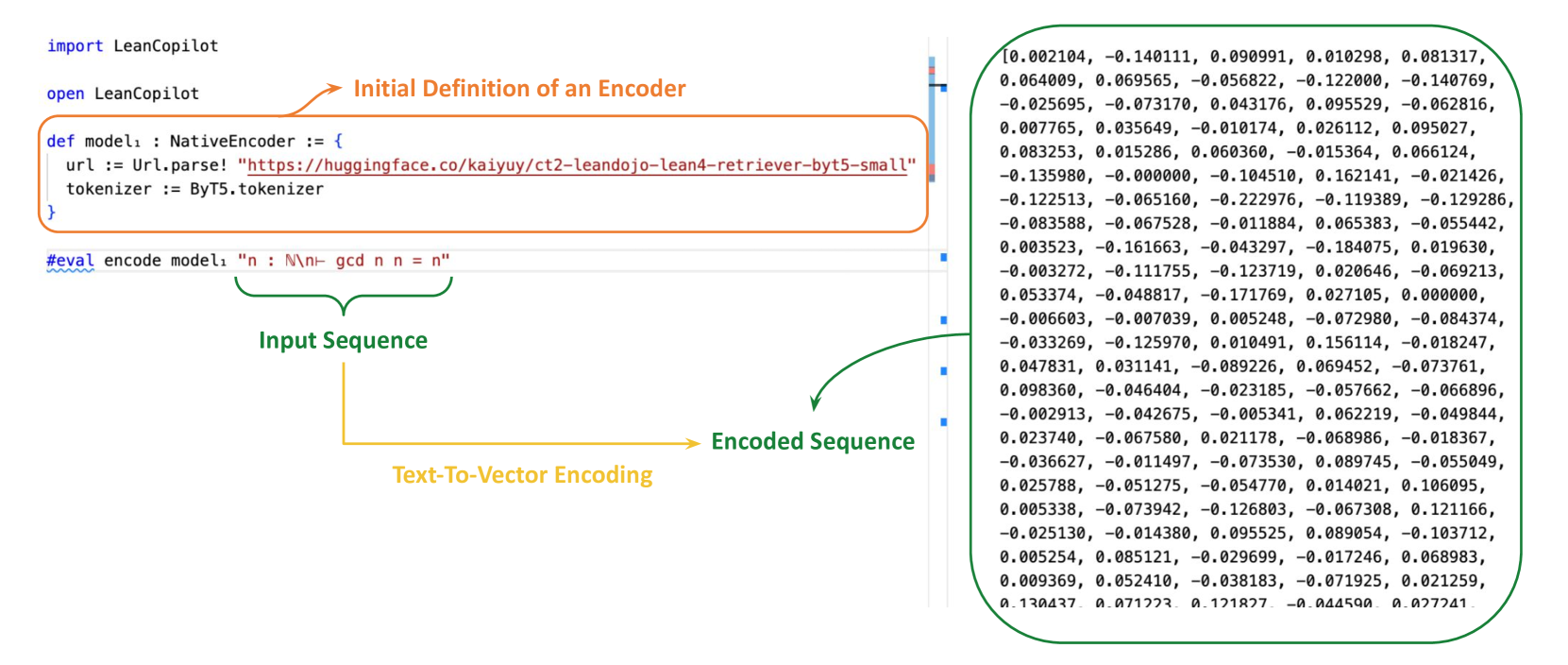
## Diagram: Text-To-Vector Encoding Process
### Overview
The image illustrates a text-to-vector encoding process using LeanCopilot. It shows the initial definition of an encoder, an input sequence, and the resulting encoded sequence. Arrows indicate the flow from input to encoded output.
### Components/Axes
* **Header:**
* `import LeanCopilot`
* `open LeanCopilot`
* **Initial Definition of an Encoder:**
* Contained within an orange rounded rectangle.
* `def modelı: NativeEncoder := {`
* `url := Url.parse! "https://huggingface.co/kaiyuy/ct2-leandojo-lean4-retriever-byt5-small"`
* `tokenizer := ByT5.tokenizer`
* `}`
* **Input Sequence:**
* Green curved bracket pointing to the line: `#eval encode model1 "n: N\n- gcd n n = n"`
* **Text-To-Vector Encoding:**
* Yellow arrow pointing from the input sequence to the encoded sequence.
* **Encoded Sequence:**
* Green curved bracket pointing to a block of numerical data.
* Numerical data is a list of comma-separated floating-point numbers enclosed in square brackets.
### Detailed Analysis or ### Content Details
* **Initial Definition of an Encoder:**
* The encoder is defined as `NativeEncoder`.
* The URL points to a Hugging Face model: `https://huggingface.co/kaiyuy/ct2-leandojo-lean4-retriever-byt5-small`.
* The tokenizer used is `ByT5.tokenizer`.
* **Input Sequence:**
* The input sequence is defined as `"n: N\n- gcd n n = n"`.
* **Encoded Sequence:**
* The encoded sequence is a list of floating-point numbers. Here are the first few values:
* `0.002104, -0.140111, 0.090991, 0.010298, 0.081317`
* `0.064009, 0.069565, -0.056822, -0.122000, -0.140769`
* `-0.025695, -0.073170, 0.043176, 0.095529, -0.062816`
* `0.007765, 0.035649, -0.010174, 0.026112, 0.095027`
* `0.083253, 0.015286, 0.060360, -0.015364, 0.066124`
* `-0.135980, -0.000000, -0.104510, 0.162141, -0.021426`
* `-0.122513, -0.065160, -0.222976, -0.119389, -0.129286`
* `-0.083588, -0.067528, -0.011884, 0.065383, -0.055442`
* `0.003523, -0.161663, -0.043297, -0.184075, 0.019630`
* `-0.003272, -0.111755, -0.123719, 0.020646, -0.069213`
* `0.053374, -0.048817, -0.171769, 0.027105, 0.000000`
* `-0.006603, -0.007039, 0.005248, -0.072980, -0.084374`
* `-0.033269, -0.125970, 0.010491, 0.156114, -0.018247`
* `0.047831, 0.031141, -0.089226, 0.069452, -0.073761`
* `0.098360, -0.046404, -0.023185, -0.057662, -0.066896`
* `-0.002913, -0.042675, -0.005341, 0.062219, -0.049844`
* `0.023740, -0.067580, 0.021178, -0.068986, -0.018367`
* `-0.036627, -0.011497, -0.073530, 0.089745, -0.055049`
* `0.025788, -0.051275, -0.054770, 0.014021, 0.106095`
* `0.005338, -0.073942, -0.126803, -0.067308, 0.121166`
* `-0.025130, -0.014380, 0.095525, 0.089054, -0.103712`
* `0.005254, 0.085121, -0.029699, -0.017246, 0.068983`
* `0.009369, 0.052410, -0.038183, -0.071925, 0.021259`
* `0.130437, 0.071223, 0.121827, -0.044590, 0.027241`
### Key Observations
* The diagram illustrates a complete process from defining an encoder to generating an encoded sequence from an input sequence.
* The encoder uses a pre-trained model from Hugging Face.
* The encoded sequence is a vector representation of the input text.
### Interpretation
The diagram demonstrates how a text input can be transformed into a numerical vector representation using a pre-trained encoder model. This process is fundamental in many natural language processing tasks, where text needs to be converted into a format that machine learning models can understand and process. The use of a Hugging Face model suggests leveraging transfer learning to improve the performance of the encoding process. The encoded sequence represents the semantic meaning of the input text in a high-dimensional space, enabling tasks like text classification, similarity comparison, and information retrieval.