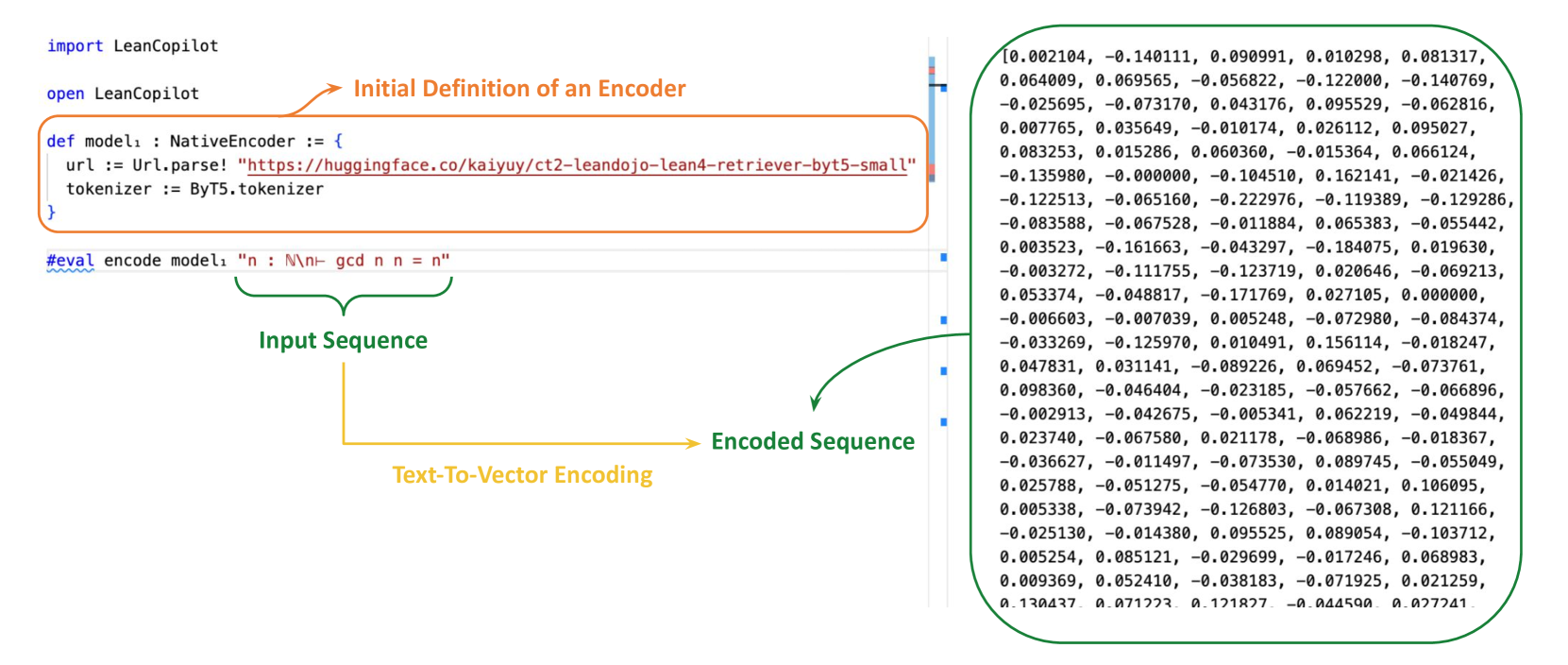
## Diagram: Text-to-Vector Encoding Workflow
### Overview
The image depicts a technical workflow for converting text input into a numerical vector representation using a pre-trained language model. It includes code snippets, model definitions, and a list of encoded numerical values.
### Components/Axes
1. **Code Section (Left Side)**:
- **Labels**:
- `import LeanCopilot` (blue text)
- `open LeanCopilot` (blue text)
- `def model1 : NativeEncoder := { ... }` (orange text)
- `url := Url.parse! "https://huggingface.co/kaiyuy/ct2-leandojo-lean4-retriever-byt5-small"` (orange text)
- `tokenizer := ByT5.tokenizer` (orange text)
- `#eval encode model1 "n : N\n\\n\\- gcd n n = n"` (green text)
- **Flow**:
- Code imports and initializes a model (`model1`) using a Hugging Face URL and a tokenizer (`ByT5`).
- The `#eval` line triggers the encoding of the input sequence `"n : N\n\\n\\- gcd n n = n"`.
2. **Encoded Sequence (Right Side)**:
- **Labels**:
- `Encoded Sequence` (green text)
- **Content**:
- A list of 100 numerical values (floating-point numbers) representing the encoded vector.
- Example values: `[0.002104, -0.140111, 0.090991, ...]` (truncated for brevity).
3. **Annotations**:
- Arrows connect the code to the encoded sequence:
- Green arrow: `Input Sequence` → `Encoded Sequence`
- Yellow arrow: `Text-To-Vector Encoding`
### Detailed Analysis
- **Model Definition**:
- The model (`model1`) is defined as a `NativeEncoder` with a URL pointing to a Hugging Face repository (`kaiyuy/ct2-leandojo-lean4-retriever-byt5-small`).
- The tokenizer is specified as `ByT5.tokenizer`, indicating the use of a BERT-based tokenizer.
- **Encoded Sequence**:
- The numerical values are the output of the model's encoding process.
- Values range from approximately `-0.140111` to `0.162141`, with most values clustered between `-0.1` and `0.1`.
- The sequence is structured as a 1D array of 100 elements, likely corresponding to the tokenized input.
### Key Observations
1. **Input-Output Relationship**:
- The input sequence `"n : N\n\\n\\- gcd n n = n"` is encoded into a dense vector of 100 dimensions.
- The model appears to be a BERT-like transformer, as suggested by the `ByT5.tokenizer` reference.
2. **Numerical Patterns**:
- The encoded values show no obvious monotonic trend but exhibit variability, typical of transformer-based embeddings.
- Some values (e.g., `-0.140111`, `0.162141`) are outliers in magnitude compared to others.
3. **Code Structure**:
- The use of `LeanCopilot` suggests a Lean-based programming environment for formal verification or model development.
- The `#eval` directive implies evaluation of the encoding function in a computational context.
### Interpretation
- **Purpose**: The diagram illustrates how text is transformed into a numerical representation using a pre-trained model, a common step in NLP pipelines for tasks like similarity search or classification.
- **Technical Insights**:
- The model (`model1`) is likely a fine-tuned version of a BERT-based architecture, given the `ByT5.tokenizer` reference.
- The encoded sequence’s structure (100 dimensions) aligns with typical BERT embeddings (e.g., 768 dimensions for BERT-base, but this may be a custom or truncated version).
- **Ambiguities**:
- The exact model architecture (e.g., BERT, RoBERTa) is not explicitly stated, though the tokenizer hints at BERT.
- The input sequence’s meaning (`"n : N\n\\n\\- gcd n n = n"`) is unclear without context, but it may represent a mathematical or logical statement.
### Spatial Grounding
- **Legend**: No explicit legend is present, but the numerical values are listed in a single column on the right.
- **Positioning**:
- Code is on the left, model definition in the center, and encoded sequence on the right.
- Arrows guide the flow from code → model → encoded output.
### Trend Verification
- The encoded sequence does not show a clear upward or downward trend, as expected for high-dimensional embeddings.
- Values are distributed across the range `[-0.14, 0.16]`, with no dominant pattern.
### Component Isolation
1. **Header (Code Section)**:
- Focuses on model initialization and tokenizer setup.
2. **Main Chart (Encoded Sequence)**:
- Displays the numerical output of the encoding process.
3. **Footer (Annotations)**:
- Arrows and labels clarify the workflow.
### Final Notes
- The image emphasizes the technical process of text-to-vector encoding rather than visualizing data trends.
- The absence of a chart or graph suggests the focus is on the code and its output rather than statistical analysis.